
Software programming is not (yet) part of a conventional legal education curriculum in the UK and other parts of the world. To read or write computer code may appear a bit intimidating to most law students who are not computationally trained. This fear is quite understandable as people can be naturally frightened (and awed) by cryptic stuff like computer code written in a highly formalised and abstract manner. It is a kind of fear not dissimilar to the one that most lay people (not trained in law) feel about legal jargon or legalese, which also seems to hold mystical power in a somewhat enchanted legal world. (Think about those incantation-like terms such as “promissory estoppel” for non-lawyers.) It is not a coincidence that law is often called “code” given its cryptic nature similar to computer “code”.
In many ways, a formal legal system and a (Turing-complete) computer are similar in the sense that both attempt to build their respective abstract models (with formalised symbols) for understanding the complex real world. It is important to note that neither legal code nor computer code is the same as those entities, events or relations in the real world, but the former merely serve as abstract representation of the latter. For legal code, it is about representing the real social relation in an abstract way, which can be further used to provide normative guidance for human behaviour. For computer code, it is about capturing the real physical relation of electronic components that can be used to complete computational tasks.
My choice of computational tools for legal research is based on two criteria. First, they need to be free and open source software (FOSS), which means their source code is available for public examination and reuse. This is crucial for making a legal computational research project sustainable and reproducible. Second, these tools need to be plain-text based,[1] and I, in principle, avoid anything overly dependent on graphic user interfaces (GUIs). This is because a text-based workflow will leave a much more transparent audit trail for other researchers (as well as my future self) to re-examine and reproduce a computational process and possibly its result. It is much harder to conduct reproducible research with GUI-based tools simply because hand movements by clicking and pointing a computer mouse are difficult to be recorded and reproduced. In addition, plain text can be version controlled by software like Git, [2] Git allows programmers to collaborate to build jointly authored projects. Git is not limited to software, but it can be used for any text-based project (e.g. a collaborative book such as the brilliant The Turing Way handbook for reproducible data science:). Git is also good at recording authorial information of contributors. For example, a simple bash command like “`$ git log | grep ^author -i | sort | uniq“` can quickly list contributors to a Git-controlled project with a reasonable amount of details.
With this in mind, I wish to show three categories of computational tools that have helped me to explore and curate legal knowledge in the field of music copyright as an example. The first category covers music notation software, which is necessary to generate scores related to music snippets from litigated works. Lilypond and Sonic Pi , which are two of my all-time favourites, fall into this category. Lilypond is a music engraving package belonging the legendary GNU project. It uses LaTeX-like syntax (again with plain text) for making (or “engraving”) high-quality digital music sheets. For example, in a 1976 US music copyright case, the formal Beatle George Harrison’s song “My Sweet Lord” was ruled to have subconsciously copied the plaintiff’s song “He’s So Fine”. [3] The actionable copying was established by two repeated motifs present in both complaining and defending songs. (Judge Owen hand-wrote the notation of these two motifs into the court ruling!) One of the two motifs in this litigation involves three sequential notes “sol-mi-re”. For a Lilypond-savvy judge, he or she only needs to type a simple command “`\relative c” {g e d}“` and the scored music snippet can be elegantly engraved as follows:
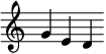
It is worth noting that LilyPond only prints out music notes on staff lines, but it does not make any sound. This is the place where the music programming language Sonic Pi fills the gap. Sonic Pi is developed by Sam Aaron (at Cambridge). It is intended to be a user-friendly scripting language for people to express their music ideas algorithmically. If a curious music copyright lawyer wants to hear the sound of music works in disputes (for the purpose of similarity analysis), Sonic Pi will do the job. Use the same “sol-mi-re” example from the above-mentioned “My Sweet Lord” case: one can simply type the command “`play_pattern [:g, :e, :d]“` into the Sonic Pi IDE and the melody will be played. Of course, one may combine LilyPond and Sonic Pi together to do much more sophisticated analysis of similar songs that are litigated. (As a side benefit, do not forget Sonic Pi is originally designed for live music coding. This opens up opportunities for lawyers who aspire to moonlight as DJs of “algorave” dance music when they are not doing their boring legal work!)
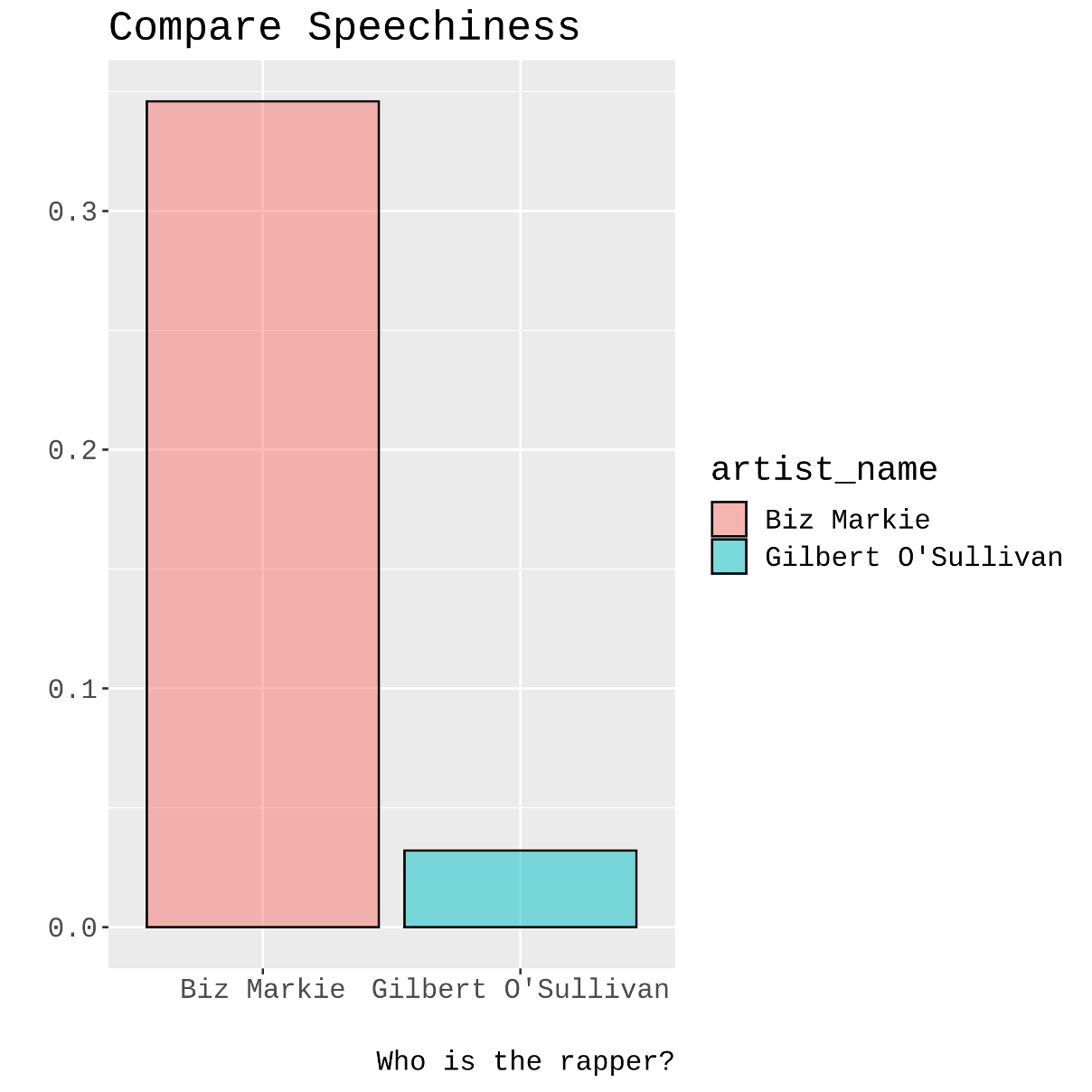
The second category covers programming languages including R and Python for doing exploratory data analysis (EDA). R is a language dedicated to computational statistics and graphics. Python is a general-purpose language that can do many more things beyond what R is capable of. I find Python’s package management to be a bit complicated, and it demands much more care. As a result, I mainly use Python (and MicroPython) for programming my Raspberry Pi (the computer) and Pi Pico (the microcontroller), but I prefer R for EDA tasks. For music copyright research, I regularly use “tidyverse” and “spotifyr” (two R package) together to obtain, wrangle and visualise music data from Spotify. tidyverse is a collection of R packages (including dplyr, tidyr, ggplot2 and many more) that are designed for curating and exploring datasets. spotifyr is a brilliant package that wraps Spotify Web API for R users to get audio feature data of songs available on Spotify. The combination of the two allows me to have a glimpse into multidimensional dataframes of Spotify music works and this cannot be easily achieved with LilyPond and Sonic Pi (which mainly deal with the compositional aspect of music). With the help of spotifyr, it is easy to obtain a wide range of audio feature parameters of Spotify soundtracks (such as “danceability”, “energy”, “loudness”, “speechiness”, “acousticness” etc.) I can then use R’s visualisation package “ggplot2” (part of “tidyverse”) to compare tracks by different artists. For example, one may try to compare the “speechiness” parameter of Biz Markie and Gilbert O’Sullivan’s respective songs on Spotify. (These two artists were the plaintiff and the defendant in the landmark music sampling case Grand Upright Music v. Warner Bros. Records, 780 F. Supp. 182 (1991), where the judge began the ruling with a stern warning: “Thou shalt not steal.”) With a few lines of R code, it is not surprising to find Biz Markie’s “speechiness” score is much higher than O’Sullivan’s. (I am convinced that Biz Markie is a rapper!)
The third category covers text editors, which are essential for a plain-text workflow. My editor of choice is Emacs, which is an editor equipped with a dialect of LISP programming language. Emacs is highly extensible and customisable. If one needs certain new features for this editor, one can just write one’s own. (Of course, this involves some learning curves and one is expected to spend quite some time learning to write code in LISP.) For example, I sometimes need to check Stanford Encyclopedia of Encyclopedia for certain philosophical concepts in the middle of writing, but I do not wish to get distracted by opening an external web browser. (It can be dangerous to open a browser with a search engine and then start mindless browsing). So I write a simple function that extends Emacs’s built-in browser called “eww”, which allows me to focus on reading the encyclopedia’s entries within Emacs with minimum distraction. (I share this LISP function among others here) In short, I use Emacs for both programming and non-programming tasks because it can bring coding and prose writing seamlessly into one single workflow in the spirit of what Donald Knuth calls “literate programming”.[4]
Finally, I want to conclude with a caveat with the use of these computational tools. I find some of these tools do not always make my research life easier in an immediate way. Instead, they can sometimes make things a bit frustrating, because a self-taught programmer like me has the tendency to see things to be more complicated than they should be. One source of such frustration comes from the so-called “tutorial purgatory” problem, where an autodidactic learner can easily spend a disproportionate amount of time studying an unfamiliar topic without making any progress. This learner is thus stuck in a purgatorial situation as no one would tell him/her to move onto the next topic. [5] However, I still strongly believe that learning by trial and error should be a built-in component of computationally motivated legal research. I expect to pay a price and I envision that there will be uncertainty in a research journey. All in all, I have so far enjoyed experimenting with different computational tools and methods for my research. Even though some tools do not yield immediate and quick results as desired, I do not regret doing it. This is because coding itself can be intrinsically fun (and even addictive) without external rewards. I just enjoy doing it for its own sake and some degree of frustration can be tolerated.
[1] Kieran Healy, The Plain Person’s Guide to Plain Text Social Science (2019) https://kieranhealy.org/publications/plain-person-text/ accessed October 1, 2020.
[2] Git was developed by Linus Torvalds and many volunteer contributors, who were dissatisfied with the proprietary version control software for managing the Linux kernel project.
[3] Bright Tunes Music Corp. v. Harrisongs Music, Ltd., 420 F. Supp 177 (1976)
[4] Donald E. Knuth, “Literate Programming” (1984) 27 The computer journal 97.
[5] For some sensible advice on how to avoid being stuck in a tutorial purgaotry, see Daniel Chae, ‘How I Escaped Tutorial Purgatory – and How You Can, Too’ (freeCodeCamp, 23 November 2020) https://www.freecodecamp.org/news/escape-tutorial-purgatory/