On 17 March 2021, the first letter was entered into our project database by Sarah Fox. The letter was written by Dorothy Wright, on 31 May 1746, to her daughter Catherine. Dorothy was visiting another daughter who had recently given birth, but she dared not leave because the new mother, ‘is so fearfull she neather Dar Dress nor Underess the Child’.[1] One year later, on 17 March 2022, Emily Vine has entered our most recent letter, number 1324 in our database. Henrietta Ingram happily reassured her younger sister that ‘you have the most pleasing way of relateing things that ever any Little Girl had’, before imparting the sad news that her friend Jane was, ‘taken very ill of an inflamation in her Bowels of which disorder she expired in less than a week’.[2] From new life to lamentable death, such letters are a remarkable and under-used record of daily, and embodied, life.
Our bespoke relational database includes fully searchable transcriptions and digital photographs of these letters. It also enables us to label the letters in a variety of ways that are designed to answer our research questions. What were eighteenth-century people’s quotidian ideas and experiences of the body? How were these affected by letters and the social relationships that letters represent? We have come to realize that this database is not only a powerful research tool but will enable us to deliver a hugely significant body of manuscript material to researchers and the public by the end of the project – in 2024.
This corpus of letters is unlike any other set of fully transcribed eighteenth-century manuscripts to be made publicly available before. It is also highly curated. Needless to say, any chosen letter needs to discuss the body. Letters have also been selected to represent a very broadly defined ‘middling sort’, to ensure an equal number of female and male authors, and to include non-conforming Protestants, Catholics and Jews, alongside conforming Protestants. This is a British project and we have letters from England, Scotland, Wales and Ireland, but we follow our British letter-writers – and their bodies – when they travel overseas, or when their correspondents do. We have letters written from the Caribbean, from France and from America, for example. This is a project about Britons as much as it is about Britain. In so many ways, the reach of this collection of manuscripts is unrivalled.
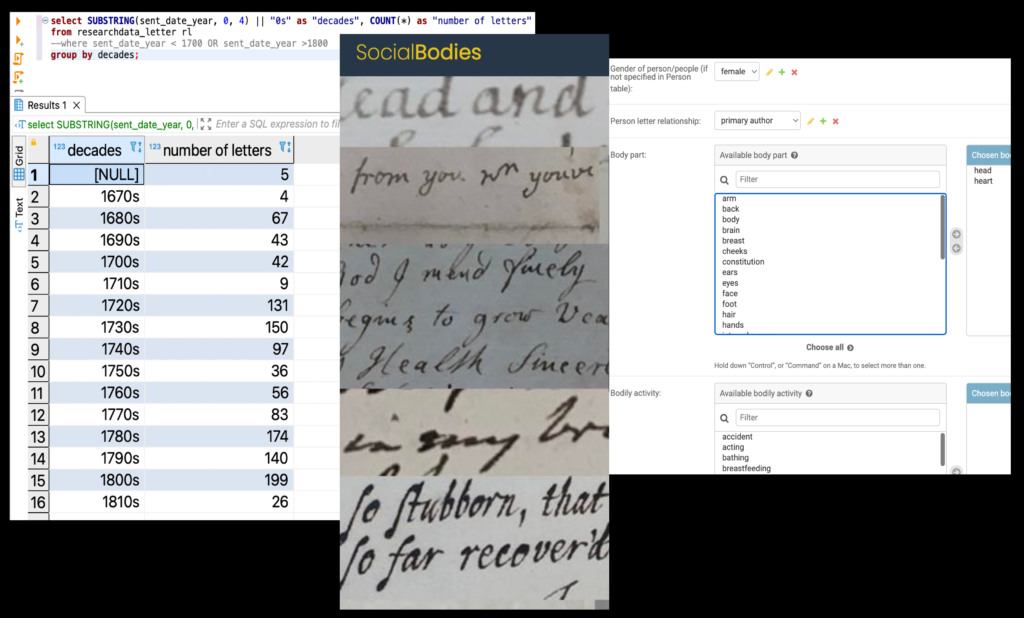
The painstaking work really begins once we are in possession of a letter. One of the team takes a photograph using a dedicated app – Capturing the Past – that names the files with the repository and document number. Letters are then fully transcribed.[3] After transcribing, we label or subject index the information by entering data into three separate tables. First, there are 20 fields in the ‘Letter’ table, which record information such as the date of the letter and an approximation of the proportion of the letter has relevant body content. Second is the ‘Person’ table which contains records for each letter writer, recipient or subject (as long as we have anything more than a name for them); 15 fields record details such as gender, religion, rank, occupation and marital status.
But the beating heart of our database is the third table: ‘Letter person’. This is where all the body or emotion content is recorded. This table represents any one person’s body in any single letter: this could be the author, the addressee or another person who is a subject in the letter. Each letter can generate several ‘letter-persons’, and they do. Today, there are 4847 letter persons in our database. That is, we think, a staggering figure.
For each of those individual figures we record details about their bodies using 19 fields available for each ‘letter person’ (13 of which can each include a range of items, some up to 53 different labels). Body part, bodily activity, life stage, emotion, sensation and treatment are amongst the fields we complete. And because this is a relational database, we can ask questions that link the three main tables. Were women associated more commonly with gout than men? Did references to medical treatment increase over time? Did Catholic letters discuss the body at greater length than Protestants? Our ability to answer such questions transforms the sort of cultural history of the body and embodied experiences we are able to write.
Undoubtedly, designing such a database takes time and expertise. Our database has benefitted from the expertise of many colleagues, especially Mike Allaway, our Software Engineer at the University of Birmingham, and the two external members of our Digital Advisory Board, Adam Crymble and Zoe Alker. Once up and running, inputting this volume of data is a time-consuming process and one that involves numerous individual interpretations by the project’s researchers, even if these are informed by subject expertise. And while impressive in scope, the database cannot account for the innumerable variables at work in familiar letters. Letters were not simply repositories of data but served as narratives, narratives that often sat within a longer, episodic, (usually) two-sided narrative created through back-and-forth correspondence. Nevertheless, and once the team has been trained in the requisite code, the digital tools can produce sometimes dizzying results. These can serve as a starting point which lead back to other – long-hand, traditional – tools of analysis which include deep or close reading.
Yet digital research tools used on a corpus of this kind also generate new questions that are not just quantitative but are qualitative and interpretive, and that can change the way we understand eighteenth-century letters, what they communicated and how they worked in social relationships.[4] They allow us to compare sets of correspondence to one another and to explore a long-running correspondence over time, and to track emotions or embodied experiences across these. The dividend for historians will be considerable – certainly the excitement amongst the project team is palpable. As important, though, is the impact for other users who will be able to devise their own questions once the database is public. This public access – alongside our ambition to engage ‘digital citizen transcribers’ in crowd-source transcription events – stand to engage new audiences in the everyday lives of ordinary Britons during the period 1680-1820.
[1] Dorothy Wright to Catherine Elliott, 31 May 1746, LD1576/1[13], Sheffield Archives.
[2] Henrietta Ingram to Nanny [Her sister], 24 February 1759, MS. Don. c. 190 f.62, Bodleian Library.
[3] Most of our letters are transcribed by the two postdocs on the project, Sarah Fox and Emily Vine, but some of our letters have also been transcribed by Natalie Hanley-Smith.
[4] Leighton Evans and Sian Rees, ‘An Interpretation of Digital Humanities’, in David M. Berry (ed.), Understanding Digital Humanities (Palgrave Macmillan, Basingstoke, 2012), pp. 34-6; Tim Hitchcock, ‘Confronting the Digital; Or How Academic History Writing Lost the Plot’, Cultural and Social History, 10:1 (2015), pp. 19-20.