La revisión de vuestras transcripciones del Texto 2 nos ha deparado una muy buena noticia que, en realidad, ya intuíamos: por lo general, estamos comprobando cómo el nivel de precisión en las transcripciones ha ido mejorando en las dos últimas semanas. ¿En qué habéis mejorado? Muy fácil, os lo contamos a continuación, pero desde ya os agradecemos todo el esfuerzo invertido en fijar más la atención en las transcripciones y realizarlas con un poco más de pausa y reflexión: los resultados son muy positivos. ¡Enhorabuena!
Antes de nada, os enseñamos en la imagen de abajo la transcripción correcta del Texto 1 (en visualización abreviada y expandida) tal como la deberíais haber visto en la plataforma una vez terminado el trabajo. Si quieres, puedes compararlo con tu versión. Si detectas algo que no comprendes, ¡háznolo saber, por favor!: estamos siempre a tu disposición.

En primer lugar, es muy importante confirmar que poco a poco va descendiendo el número de errores o lapsus relacionados con la variación gráfica del manuscrito C con respecto al texto base de E1. Recordad, en este sentido, que en nuestro manuscrito es mucho más frecuente encontrar grafías como <ç> (cedilla), <j> (con valor vocálico o consonántico) y <v> (en inicio de palabra). En el primer caso (<ç> cedilla), fijaos en los ejemplos que entresacamos del texto: *ciertas > çiertas, *cibdat de francia > çibdat de françia, *cibdadanos > çibdadanos. A veces la cedilla no se lee tan claramente, como en el caso de “françia”, pero ahí está (es ese pequeño borrón de tinta debajo de la <c>). Siempre que veáis alguna mancha de tinta presuntamente extraña, por muy pequeña que sea, prestad atención y sospechad, porque casi siempre esa pequeña mancha tiene un sentido: algunas veces nos interesará (como en el caso de una cedilla o de una lineta), pero en otros no (por ejemplo, el punto o raya colocada habitualmente encima de la <y>).

En el caso de la <i/j>, también estaréis comprobando, cada vez con mayor consciencia, que en el manuscrito C es raro encontrar palabras que empiecen por <i> y que normalmente es más frecuente encontrar una <j> cuando en el texto base (E1) aparece la i latina: ejs. *traiano > trajano, *iusticia > Justiçia, *mouio > moujo, *tenien > tenjen.

En los dos últimos casos (moujo, tenjen), fíjate en que la <j> se sitúa después de una letra (<n>, <u>) cuya morfología se puede confundir con dos <i> latinas o, peor, con una <m> si le añadimos un <i> a continuación. De ahí que, con cierta frecuencia, se extienda hacia abajo el trazado de la <i>, formando una <j>, para evitar esa posible confusión y facilitar la legibilidad del texto por parte de los lectores y revisores (medievales). En el Módulo 1 nos referimos a estas cuestión.
En cuanto a la distribución <u/v>, también se nota que habéis reparado en que en el manuscrito C aparece con más frecuencia <v> en inicio de palabra, frente a E1 donde es más habitual encontrar <u>: ejs. *uez > vez, *una uilla > vna villa, *un > vn.

Ahora bien, al tiempo que fijáis en vuestra memoria esa tendencia gráfica de C (recordad el concepto de usus scribendi del que hablábamos aquí), lo cual es muy útil para incrementar la precisión de vuestras transcripciones, también os habréis dado cuenta de que no es una regla sistemática (por eso hablamos de tendencia), ni mucho menos. Un buen ejemplo es la forma “uinieron” (y no es el único caso, por supuesto: uençio, una, etc.): cabría esperar, de acuerdo con el usus scribendi del manuscrito, que el copista escribriera esta palabra con <v> inicial (*vinieron) o que alargara alguna de las <i> latinas (<j>) para evitar esa confusión con la letra precedente de la que hablábamos antes (*ujnieron, *uinjeron, *ujnjeron, *vinjeron). De hecho, quizás te haya costado identificar la palabra en una primera lectura: podríamos leerla como *uuneron, *iumeron, *miueron, etc. Por contexto y por el texto base, claro está, sabemos que se refiere a la forma verbal ‘vinieron’.

Pero… ¿por qué el copista no ha seguido aquí la práctica habitual, en su modo de escribir, de iniciar la palabra en <v> o incluir una o más <j> para mejorar la legibilidad? No lo sabemos, pero no es en absoluto infrecuente que en el arduo proceso de copia algunas veces el amanuense se deje llevar, de manera inconsciente, por la escritura del modelo que está copiando, a diferencia de otras ocasiones en las que sí actúa con mayor innovación de acuerdo con sus preferencias gráficas. O quizás haya alguna otra explicación complementaria…
Fijémonos un poco más, afinemos la vista y, si es necesario, hagamos uso de la lupa (sí, aunque no lo sepas y no te lo creas, es posible que tengas una vieja lupa guardada en algún cajón oscuro de tu casa… :-D). Quizás todavía no seas consciente de ello, pero seguro que en algún momento te has preguntado por qué, de vez en cuando, aparecen unos minúsculos rasgos oblicuos encima de ciertas palabras. A veces son simples rasgueos producto del acto de levantar la pluma y dejar de escribir: esto también nos pasa a nosotros, cuando escribimos con un bolígrafo o pluma, pues al levantar la mano a veces quedan restos de tinta en el papel. Sin embargo, si te fijas en la escritura de C, verás cómo es bastante frecuente (aunque no llega a ser sistemático) que la <i> latina (e incluso la <j> y la <e>) vaya acompañada en el interlineado superior de una pequeña marca diagonal siguiendo la trayectoria oblicua de la letra. En el siguiente fragmento, repara en que las formas línaje, uínieron, ulpío, auíe, rreçibío, sennorío, inperío incorporan ese pequeño trazo diagonal, que se suele denominar ‘plica’ o ‘ápice’ cuando tiene un valor distintivo, es decir, cuando se usa para distinguir con claridad la <i> latina de otras letras contiguas. No siempre es necesaria su presencia y, de hecho, muchas veces es mecánica, pero en formas como “uínieron” puede ayudar al lector a distinguir esa <i> de las letras contiguas (<u>, <n>), evitando, así, una posible confusión.

Aún en relación a la grafía <j>, algunas personas nos han preguntado, muy atinadamente, por qué transcribimos a veces <j> y otras <J>, es decir, por qué unas veces en minúscula y otras en mayúscula. La pregunta es lícita porque lo que vemos en el manuscrito es que se trata de una <j> de trazado alto (la letra sobresale no solo hacia abajo sino también hacia arriba respecto a la altura base de la caja de escritura). La pregunta es interesante porque ya veréis que la diferencia <j, J> tiene implicaciones importantes a nivel cronológico en relación con la evolución de las escrituras góticas. Pero, en primer lugar, ¿qué es lo que nos interesa reflejar en nuestra transcripción? Lo más importante es, como ya dijimos antes, la distinción entre la <i> latina (más frecuente en E1) y la <j> (más frecuente en C). La siguiente cuestión es: ¿por qué transcribimos “trajano” (con <j>) y “Justiçia” (con <J>), si la forma de la letra es idéntica (trazado alto)? La respuesta es muy sencilla y tiene que ver con una convención que nos evita complicar aún más el resultado de la transcripción: cuando la <j> se encuentre en posición inicial transcribimos como si fuera mayúscula (<J>), con independencia de que se trate de un nombre propio o no (Justiçia, y no *justiçia; Julio, y no *julio), y cuando la <j> está en cualquier otra posición (interna), transcribimos como si fuese minúscula (trajano; no *traJano). En resumen, cuando veas una <j> la transcribes en mayúscula si inicia palabra, y si no la transcribes como minúscula.

¿Y qué implicaciones tiene a nivel cronológico la presencia de esta <j> de trazado alto, por oposición a la <i> latina o a la <j> de trazado bajo o largo (como la <j> actual del castellano)? Si tienes interés en ello, te recomendamos leer este artículo (de la autoría de Mª del Carmen Fernández López). En él, resumiendo mucho, se confirma que hacia mediados del siglo XIV, en la tradición escrituraria castellana, se consolida el uso de la <J> de trazado alto para representar la consonante fricativa prepalatal sonora /ʒ/ (hoy evolucionada a /x/ representada por la grafía <j>: ej. Trajano). Esto quiere decir que en la segunda mitad del siglo XIV ya es muy improbable que esa consonante se represente con otra grafía distinta a esa <J> alta, mientras que con anterioridad lo habitual es que, como en el caso de C (de las primeras décadas del Trescientos), nos encontremos con una mayor variedad gráfica: <i>, <j> y <J>.
Todo lo que comentamos en estas líneas y en otras entradas del blog parecen cuestiones insignificantes, pero en realidad son muy importantes para estudiar el cambio escripto-lingüístico a lo largo del tiempo. Por eso, ¡no bajes la guarda! Es recomendable mantener una buena concentración mientras hagas la comparación entre imagen (C) y texto base (E1) para que nuestras transcripciones sean lo más precisas posibles. Y lo cierto es que ¡lo estamos consiguiendo!
Antes de pasar al mundo de las abreviaturas, dos apuntes más sobre cuestiones gráficas: seguimos detectando, aunque en menor medida, que algunos transcriptores tienden a regularizar las palabras según el uso ortográfico actual, o, por lapsus, no corrigen la ortografía del texto base: esto se nota principalmente cuando interfiere el uso actual de las mayúsculas y minúsculas. Si en la imagen vemos “rroma” y en el texto base aparece “Roma”, aunque esta última nos resulte, como es lógico, la forma más familiar, debemos sustituir la <R> mayúscula por la grafía habitual en C para representar la consonante vibrante inicial, esto es, el dígrafo <rr>. Lo mismo ocurre con “trajano”, que tendemos a dejarlo con mayúscula inicial (*Trajano), cuando en la imagen aparece normalmente en minúscula (trajano).

Ahora sí, hablamos un poco de abreviaturas: sabemos que te encantan 😀 En primer lugar, hemos notado una mejora generalizada en la elección de los valores de la lineta a través del menú de abreviaturas: ya no es tan frecuente la confusión del valor <n> por <ue> (ej. *qn > que). Algo similar ocurre con los olvidos de la indicación de la lineta (ej. *no > non, *fraco > franco), un error frecuente en el Texto 1, pero que ahora se ha reducido bastante.
Aunque en menor medida, seguimos registrando el desarrollo abreviativo de <m> ante consonante labial (<p> o <b>): recuerda que seguimos el usus scribendi, la tendencia gráfica del copista, que en este caso supone interpretar la lineta como <n> y no según la ortografía actual: *nombre > nonbre, *compañon > conpannon. Recuerda también, como en este último caso o como en la forma “espannol”, que la consonante palatal no debes transcribirla según la ortografía actual (<ñ>: *español), sino, de nuevo, según la práctica gráfica del copista, esto es: <nn>. Para ello, recuerda que debes seleccior la primera <n> y añadir una segunda <n> (n-macron) en el menú de abreviaturas; el resultado es: espan̅(n)ol, co(n)pan̅(n)on.

Hemos visto también como sigue habiendo cierta confusión con la transcripción de la palabra “como” acompañada de lineta. Como ya recordamos en otras ocasiones, en el blog y en los materiales de capacitación, no nos interesa reflejar la presencia de la lineta sobre esta palabra, porque en nuestro manuscrito la consideramos expletiva, es decir, sin ningún valor abreviativo. A diferencia de lo que encontramos en los códices alfonsíes (y en otros manuscritos del XIII), en los que se registra la forma plena “commo” con dos <m> (sin abreviar), en los manuscritos del XIV la presencia de la lineta en esta palabra no parece que tenga valor abreviativo (*commo); tan solo es un uso mecánico que recuerda la práctica abreviativa anterior, pero ya obsoleta en el XIV. Por tanto, cuando os encontréis con esta forma, tenga o no lineta, se debe transcribir simplemente “como”. Es una excepción a tener en cuenta, al igual que el punto o raya sobre la <y>, que, como ya sabéis, tampoco transcribimos: “seyendo”, “ayo”, “rriyese”, “yo”. Se trata simplemente de un elemento más de la propia morfología gráfica de la letra, que no recogemos en nuestra transcripción.

El ejemplo de “como” no es el único caso en el que obviamos la presencia de la lineta por una razón similar. Algunas personas nos han preguntado qué hacer en casos recogidos en la imagen de abajo: “mucho”, “pechos”, “derecho” y “prouecho”. Es evidente que en estos casos la lineta no tiene valor abreviativo, sino solo decorativo: si te fijas, en todos los casos la lineta cruza el asta de la <h>, pero no está abreviando nada, a diferencia de lo que vemos en otras palabras como “ħmano” (hermano) o “Ioħn” (Iohan). En realidad, es una práctica bastante habitual durante toda la época medieval, que ya empezamos a ver con frecuencia desde comienzos del siglo XIV y que se incrementa con la mayor cursividad de la letra. Solo la forma “mucho” podría ofrecer dudas (es conocida la variante con nasal “muncho”), pero transcribiremos igualmente “mucho” teniendo en cuenta el uso generalizado de la lineta con valor decorativo en el manuscrito y la ausencia de ejemplos por extenso de la variante con nasal “muncho”.

Vamos a comentar a hora una última cuestión sobre la indicación de las abreviaturas en la transcripción. Algunas personas tienen ciertas dificultades a la hora de marcar o elegir la abreviatura correcta cuando esta abrevia el valor ER. Por ejemplo, en la palabra enperador, algunos se han olvidado de indicar la abreviatura (*enpador) y otros la han marcado de manera incorrecta (*enp ͛ador). En este último caso, el resultado expandido es acertado (enperador), pero no se ha indicado el tipo de abreviatura correcta: no es el bucle o gancho supralinear ( ͛ ) que aparece en la paleta del menú de abreviaturas en el apartado de ‘símbolos especiales’, sino la <p> cruzada por la lineta en la parte inferior (p-bar), que encuentras en el apartado ‘letras combinadas’ del menú. Por tanto, la transcripción correcta es “enꝑador”, que en la versión expandida del sistema se verá así: enꝑ(er)ador. El uso de ‘ꝑ(er)’ en el Texto 2 también lo encontramos en las palabras “inꝑio” (inperio) y “ꝑdonase” (perdonase).


El valor abreviativo ER también lo habéis identificado en el Texto 2 en otras palabras en las que se utilizan otros procedimientos abreviativos. El más frecuente siempre es el ya citado gancho supralinear ( ͛ ): m ͛çed (merçed), prim ͛ (primer), m ͛ eçes (mereçes), fu ͛ e (fuere), g ͛manja (germanja), au ͛ (auer), faz ͛ (fazer), ħed ͛o (heredero), entend ͛ (entender).

Fíjate en varias cosas en la imágenes de arriba: en el segundo ejemplo (primer) verás que también aparece la <i> volada abreviando la secuencia pri-. En el ejemplo siguiente (mereces) fíjate en que, contra la tendencia habitual en C, no hay cedilla (*mereçes). Por último, en el caso de germanja, verás en la imagen una lineta al final de la palabra, pero no te confundas: se trata de la p-bar de la palabra escrita en la línea superior. Sobre el caso de heredero (penúltimo ejemplo) hablaremos a continuación.
Acuérdate de que el símbolo ( ͛ ) lo puedes encontrar, como ya vimos, en el apartado ‘símbolos especiales’ de la paleta del menú abreviativo:

Hay otro procedimiento para abreviar ER usado en el Texto 2: el uso de la lineta combinada con otras letras, como la <s> alta, la <ll> o la <h> (todas ellas con asta superior): ſ̷e / ſ̷a (sere, sera ‘seré, será), cauall̅o (cauallero), ħed ͛o (heredero). Este último ejemplo lo vimos antes, porque en la misma palabra encontramos dos formas de abreviar la secuencia ER: la ħ cruzada (her-) y el gancho supralinear (-d ͛o > -dero).

Recuerda que en todos estos casos, la manera de insertar la abreviatura es seleccionar la sílaba (her, ser, ller, etc.) y a continuación el símbolo apropiado en el menú de caracteres especiales, concretamente en la sección ‘letras combinadas’:

Vamos a acabar este post haciendo referencia a dos ejemplos de intervención correctiva del copista. Algunos colaboradores nos han expresado sus dudas a la hora de indicar en la plataforma este tipo de correcciones. Podéis encontrar más detalles en el Módulo 4 y en la Guía rápida del sistema (pestaña Practica de la web de Transcribe Estoria), pero aquí os lo recordamos.
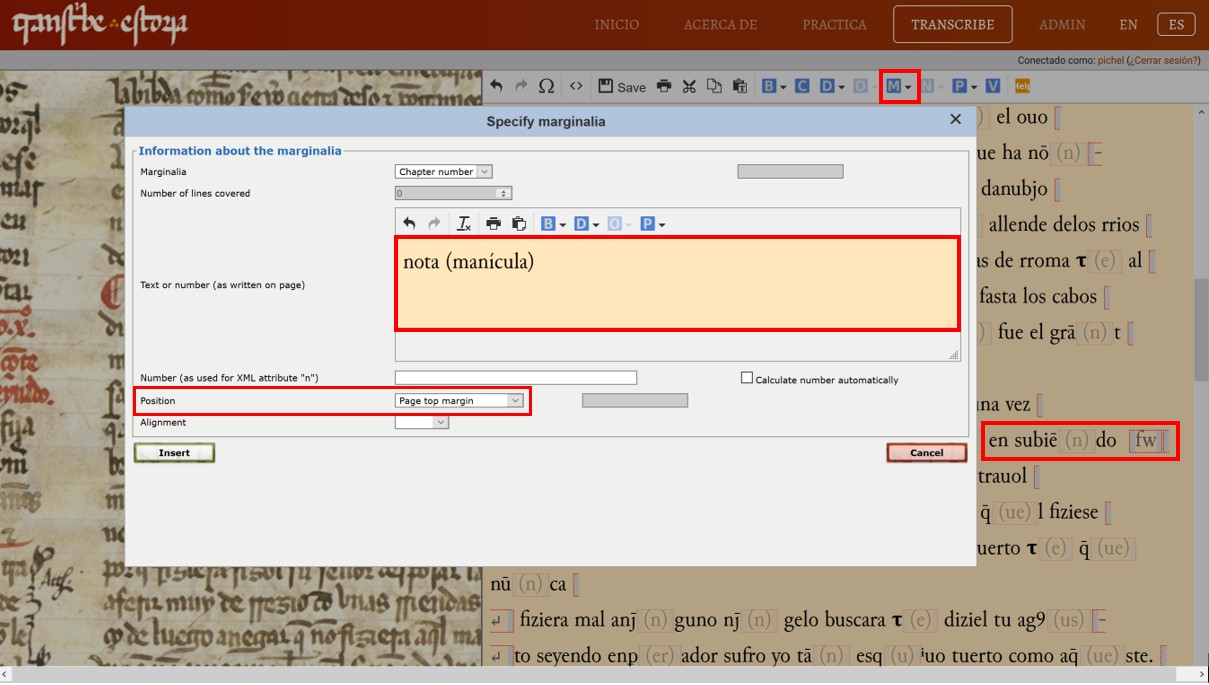
La primera corrección es fácil de identificar porque el propio copista/revisor nos lo está indicando con una preciosa manícula (en el vídeo del Módulo 2, al final, hablábamos de ello), mediante la cual señala una palabra que se ha copiado erróneamente: el amanuense copió “subiendo” en vez de “saliendo”, que es lo que aparecía en el texto base de E1. Es posible que confusión se deba no solo al parecido gráfico de las dos palabras (subiendo / saliendo) sino también a la influencia de la forma subio escrita un poco más atrás en la misma línea (“subio en su cauallo e en subiendo…”). Debajo de la manícula aparece la palabra “nota”, y alguien se puede preguntar por qué, habiéndose detectado un error, este no se corrige (por medio de raspado, tachado o sobrescritura). ¿Es posible que el copista finalmente no haya querido enmendar esa discordancia con E1? Tal vez sí, porque, en realidad la palabra subiendo tiene todo el sentido que aparezca en este contexto: “subiendo en el [cauallo]” (aunque es verdad que se repite la misma idea dos veces de manera distinga: “subio en su cauallo” + “en subiendo en el”), mientras que en E1 se hace hincapié en ‘salir de su palaçio’. Hablaremos de ello próximamente en otra entrada del blog, haciendo referencia a otros ejemplos de intervención correctiva del copista.

La pregunta ahora es: ¿cómo lo marcamos en el sistema? Muy fácil: como la forma subiendo no fue finalmente corregida por el copista/revisor, utilizamos la opción Marginalia (M) en el menú superior de la plataforma para indicar la presencia de la manícula y de la palabra “nota”. En la ventana emergente que nos aparece, únicamente debemos insertar el texto que aparece en la anotación marginal (“nota”) e indicar también la presencia de la manícula; a mayores seleccionamos la opción más apropiada en el menú ‘position’ (en este caso: ‘page top margin’). Después le damos a ‘insert’ (puedes olvidarte del resto de opciones). En la transcripción verás que aparece un recuadro rojo (‘fw’) y si le pasas el ratón por encima verás como aparece la información que introdujiste en la ventana emergente. Con esto, nos estás ayudando a identificar una nota marginal que, además, tiene valor correctivo y es muy valiosa a la hora de comparar el texto de C con el del códice alfonsí (E1).
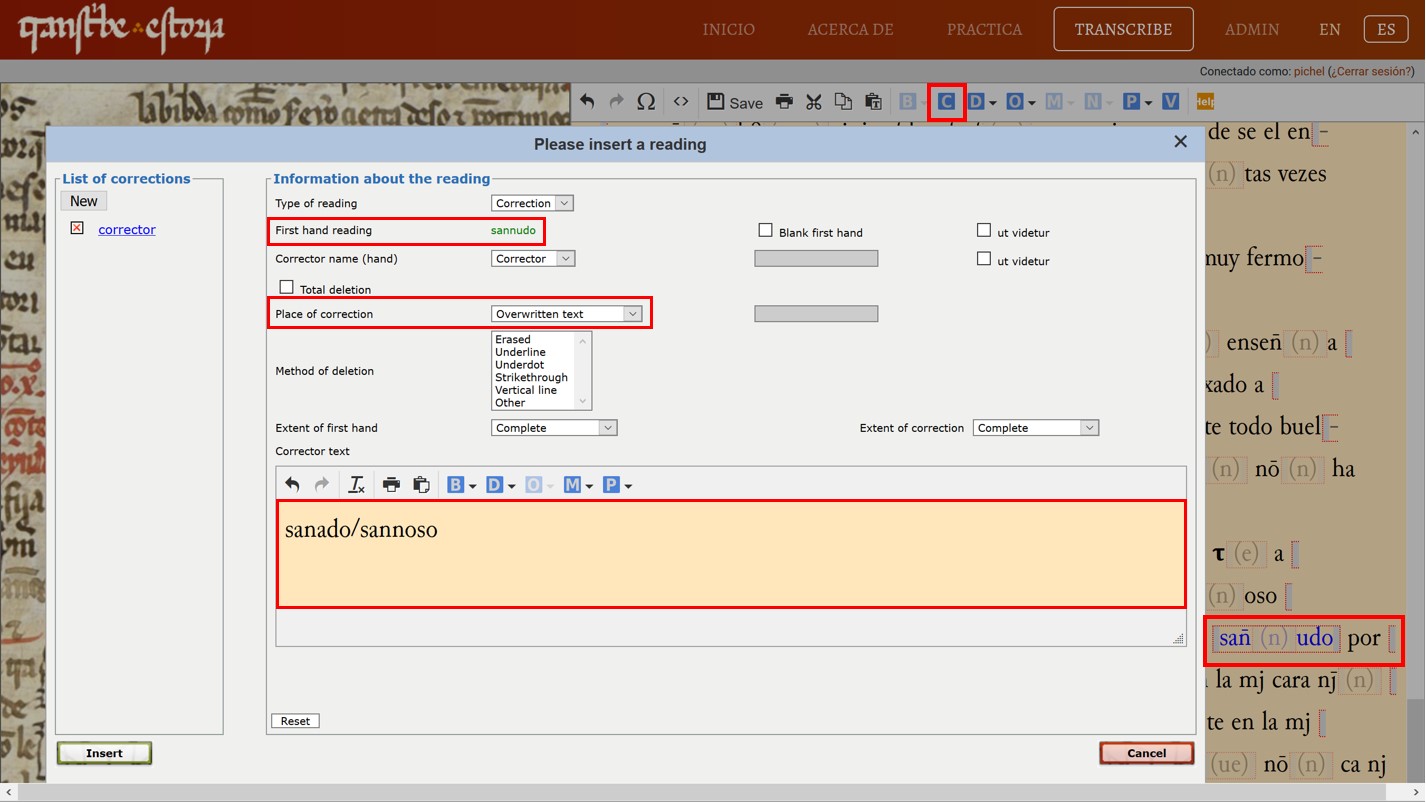
Veamos un segundo ejemplo de corrección hacia el final del fragmento del Texto 2. Como indicamos en el Módulo 4, la palabra “sannudo” fue objeto de corrección: si te fijas, al lado de la <n> parece que se escribió por error una letra redonda como <a> u <o>. Quizás el escriba estaba pensando en la forma “sanado” o se confundió con la forma “sañoso” que aparece justo por encima en la línea anterior.

En cualquier caso, para indicar esta intervención correctiva en el sistema, tenemos que seleccionar la forma objeto de corrección y utilizar la opción Corrección (C) en el menú superior de la plataforma. En la ventana emergente verás que en la parte superior (donde pone ‘first hand reading’) aparece en verde la palabra que has seleccionado en la transcripción (en este caso “sannudo”. Más abajo, en el menú ‘place of correction’ debes indicar el lugar donde se produce la corrección: en este caso, hay algo sobreescrito en la propia palabra, así que seleccionamos ‘overwritten text’. Por último, sin hacer caso a las demás opciones, indicamos en el cuadro de texto la palabra que creemos que originariamente se había escrito, es decir, la forma errónea corregida (en este caso podría ser sanado o sannoso como explicamos antes). No te preocupes si no sabes con exactitud cuál es la forma errónea que después se corrige: lo importante es que, estes seguro o no, lo indiques en la plataforma, para que luego nosotros podamos revisarlo. Una vez que introduces estos datos, le das a ‘insert’ y verás en la transcripción que la palabra sannudo ahora aparece en azul: si pasas el ratón por encima, verás la información introducida anteriormente en la ventana emergente.
Insistimos: no te preocupes si, de momento, no te sientes seguro con el manejo de la herramienta en estos casos de Marginalia o Corrección. Es lógico que así sea, porque son funciones avanzadas y hace falta práctica para dominar el sistema en este sentido. También es cierto que, al ser un proyecto piloto, estamos probando las diferentes opciones de la plataforma para poder mejorarlas en la siguiente fase del proyecto. De lo que sí puedes estar seguro es de que sin tu ayuda, nada de esto sería posible, así que no te sientas frustrado o inseguro con tu trabajo, porque, en realidad, es muy valioso para nosotros y para el futuro de la edición digital de la Estoria de Espanna.
Polly Duxfield, Ricardo Pichel y Aengus Ward