Methodology
- Preparación de los datos
- Guía de transcripción
- Presentación
- Transcripciones
- Texto crítico
- Texto de lectura
- Tabla de equivalencias Estoria Digital – Primera crónica general
La Estoria de Espanna Digital está construida de acuerdo con la visión de que una edición es crítica solo si requiere el ejercicio de un juicio editorial expresado de forma explícita, y es digital si posee una funcionalidad que no puede trasladarse al papel. Paralelamente a estas expectativas, la práctica editorial estaba muy fundamentada, por un lado, por la experiencia de proyectos anteriores, especialmente el Online Froissart y los Canterbury Tales, y por otra parte, por un principio clave, a menudo olvidado en proyectos digitales, y expresado recientemente por Paul Spence, en virtud del cual la práctica editorial debe procurar separar la preparación de los datos y su posterior presentación. En relación con esto, también éramos muy conscientes de la necesidad de evitar la toma de decisiones acerca de la preparación de datos que posteriormente podría restringir su utilidad en etapas posteriores de nuestro proyecto o, incluso, de otros. A diferencia del procedimiento adoptado por otros proyectos, la Estoria Digital apuntó a la profundidad más que a la amplitud de los datos. Así, en lugar de proponerse transcribir un gran número de testimonios con un mínimo de etiquetado y un alto grado de regularización en la representación del texto manuscrito, hemos procurado codificar toda la información material de un número de manuscritos claves limitado por el tiempo disponible. La riqueza de los datos resultantes permitiría un mayor grado de acceso digital a la Estoria al tiempo que también facilitaría la adición de información de nuevos manuscritos con el mismo procedimiento en posibles etapas futuras. La metodología aplicada a la edición se desarrolló en las siguientes etapas.
Preparación de los datos
En la fase inicial del proyecto, los miembros del equipo transcribieron los cinco testimonios utilizando XML compatible con TEI5. Inicialmente, la Dra. Bárbara Bordalejo desarrolló un conjunto de pautas de transcripción, que perfeccionó a lo largo del proyecto. Las transcripciones fueron preparadas utilizando el sistema Textual Communities de la Universidad de Saskatchewan. Esta herramienta proporciona transcriptores con la capacidad para trabajar en transcripciones de folios individuales cuyas imágenes fueran acompañadas por un espacio de transcripción. Un corrector automático del sistema Textual Communities aseguró que solo pudieran introducirse expresiones correctas en XML en el sistema. Textual Communities también permitió al editor general supervisar el progreso a través de todos los testimonios simultáneamente. Finalmente, la puesta en común en reuniones periódicas del equipo, así como la realización de consultas virtuales, garantizaron la coherencia del trabajo.
Texto base, numeración de segmentos y división textual
En paralelo con la primera etapa de transcripción fue necesario establecer un texto base (para permitir el cotejo de otros manuscritos) con una segmentación numerada. Por múltiples razones, seleccionamos el texto de E1 y E2 como base para la fase inicial de la edición. Esto, por supuesto, tiene ciertas implicaciones para el estatus de la edición; sin embargo, se decidió que el uso de estos manuscritos era la única opción viable desde el principio. En fases posteriores, por supuesto, con la incorporación de nuevos manuscritos, de la base establecida aquí podría derivarse un texto crítico hipotético. Durante el proceso de fijación del sistema de numeración de segmentos (y transcripción de E1 y E2) resultaron de gran ayuda las transcripciones del Hispanic Seminary of Medieval Studies; quisiéramos expresar nuestra gratitud al HSMS por permitirnos utilizarlas para facilitar nuestra labor. En el sistema de numeración de segmentos se ha empleado la etiqueta <div> para las divisiones capitulares, y <ab> para las oracionales. Estas fueron insertadas en el texto base, esto es, el texto de E1 y E2, por lo cual podría, en consecuencia, objetarse que dichas divisiones no son necesariamente un reflejo de la Estoria alfonsí. No fue posible la numeración del texto alfonsí, por obvias razones, pero el sistema de puntuación regular de E1 y, en una medida ligeramente menor de las secciones de 1289 de E2, significó que podíamos tener un alto grado de confianza en la numeración que establecimos a los niveles capitular y oracional, ya que hemos intentado, en la medida de lo posible, utilizar las etiquetas <div> y <ab> respetando la organización textual y la puntuación de estos códices. Ya que cualquier forma de dividir el texto -tanto para los propósitos de referencia como para su cotejo- puede tener necesariamente un cierto elemento de arbitrariedad, se consideró que el sistema elegido era la mejor solución.
Además, el sistema de numeración, aunque no sustituye propiamente el sistema de referencia de la PCG, tiene el mérito de permitir la equivalencia entre todos los testimonios, ya que secciones equivalentes en diferentes testimonios poseen todas la misma numeración. Se espera, entonces, que esta numeración pueda convertirse en un formulario estándar de referencia para todos los testimonios de la Estoria. De paso, cabría mencionar que las etiquetas <tag> en E1 y E2 permiten la referencia cruzada con los números de capítulo de la PCG, de manera que el sistema de referencia de PCG también puede ser utilizado a modo de copia de seguridad. Los criterios fundamentales en los que se basó la transcripción del texto manuscrito son:
Elementos gráficos
Hemos procurado representar con caracteres Junicode algo semejante a la forma de los caracteres individuales producidos por los escribas medievales. De todos modos, como las transcripciones de la Estoria son gráficas y no paleográficas, no buscamos diferenciar entre las diversas formas de una misma letra; como resultado, el transcriptor se ha visto obligado a utilizar su propio juicio acerca de la forma de las letras y brindar el mejor equivalente disponible.
Además, hemos seguido el usus scribendi en cada manuscrito; nuestro objetivo fue representar lo que está en la página, y no, en esta etapa de preparación, expresar una opinión en cuanto a lo que un escriba habría querido decir.
Así, por ejemplo, hemos respetado la longitud de los trazos descendentes en “i” larga, transcribiendo como “j”, incluso en aquellos casos en los cuales “i” sería lo esperable.
La fase inicial, por lo tanto, procura proporcionar equivalentes digitales de caracteres medievales sin un alto grado de intervención editorial.
Abreviaturas
Donde los transcriptores (y editor) consideraron que un escriba había empleado una abreviatura, se han utilizado los símbolos Junicode correspondientes para representar el carácter abreviado y la consiguiente etiqueta XML para expandir la abreviatura y así indicar el criterio editorial en cuanto a lo que la abreviatura representa. (Una lista completa está disponible en la Guía de transcripción; la manera en que estos están representados en las distintas formas del texto editado se trata propiamente en la sección “presentación de datos” más abajo). Para la expansión, nuevamente seguimos el usus scribendi. Esto condujo inevitablemente a cierta inconsistencia -diversas ampliaciones para lo que parece ser la misma abreviatura en diferentes partes del mismo manuscrito- pero también supuso que las secciones de cada escriba fuesen coherentes internamente. Como la materialidad del texto manuscrito es un aspecto central de esta edición, la decisión fue tomada para privilegiar, siempre que fuera posible, las particularidades del texto y no regularizar, suplir o corregir ninguna de ellas.
Marcas de abreviatura y puntuación
Del mismo modo, aunque representamos todas las marcas de abreviación, no hemos procurado diferenciar entre las diversas formas de la misma marca; así, por ejemplo, empleamos el comilla simple (‘) que representa la sílaba “er” y “re”, aunque a veces parece más un diacrítico en el manuscrito. Aunque reconocemos que esto puede reducir la utilidad inmediata de nuestras transcripciones para aquellos interesados en cuestiones paleográficas, la flexibilidad proporcionada por las herramientas digitales de búsqueda y la disponibilidad de (la mayoría) de las imágenes de los manuscritos aún resultan de gran utilidad para diferentes fines académicos. Lo mismo sucede, aunque en menor medida dado el limitado número de símbolos posibles, con la puntuación. Hemos mantenido la presencia de marcas de puntuación, pero siempre sin intentar reproducirlas exactamente en la forma de los caracteres Junicode empleados. El modo en que estos están representados en las transcripciones se desarrolla a continuación.
Guía de transcripción
La guía completa y detallada de transcripción está disponible aquí, y también en pdf.
Presentación
In presenting the front end of the edition, we were guided by two central principles: (i) that the presentation of the Estoria Digital should, where possible, take full advantage of the possibilities offered by digital tools, and (ii) as stated above, that the presentation should emerge from, but not condition, the initial preparation of data. With this in mind, a number of strategic decisions were taken about the way in which the data should be available to the user, and these were necessarily different in the case of the three principal modes of access.
Al presentar la interfaz de la edición, nos hemos guiado por dos principios centrales: (i) que la presentación de la Estoria Digital aproveche, en la medida de lo posible, las oportunidades que ofrecen las herramientas digitales, y (ii) como se ha señalado anteriormente, que la presentación se base en la preparación inicial de datos, aunque sin condicionarse a esta. Con esto en mente, se tomaron una serie de decisiones estratégicas en torno al modo en que los datos debían estar disponibles para el usuario, necesariamente diferentes para cada una de los tres principales modos de presentación.
Transcripciones
Las transcripciones están presentadas de dos maneras: abreviadas y expandidas. La primera no presenta grandes dificultades; aquí imitamos, en la medida de lo posible, las marcas de abreviatura y, por lo tanto, la escritura medieval dentro de los límites antes mencionados. Así se ha procedido, por ejemplo, con caracteres tales como ħ, ꝑ y diacríticos. La segunda resulta algo más problemática, ya que implica una serie de decisiones editoriales y deja mayor margen a la innovación (y la polémica) en la presentación.
Podría argumentarse que en las transcripciones expandidas no hay necesidad de señalar que tuvieron lugar decisiones editoriales ya que el usuario tiene disponible el equivalente abreviado, e incluso las imágenes del manuscrito. El enfoque adoptado, sin embargo, consiste en indicar de manera discreta pero abiertamente la intervención de los editores en la expansión de las transcripciones. En parte, esto procura evitar en el lector la impresión de que el texto de la pantalla esté desprovisto de toda acción editorial.
La razón principal que motivó esta decisión, no obstante, radica en que la presentación del texto digital lo permitía sin que por ello se saturase la transcripción ni se dificultara la lectura. Al proceder de este modo éramos conscientes de las posibilidades de dar un paso más allá, traspasando las barreras de la edición tradicional de textos medievales. Si concluímos que la transcripción expandida debía indicar la intervención editorial, quedaba por decidir cómo debía llevarse a cabo. Así, descartamos el modo tradicional de empleo de la cursiva para dichas acciones editoriales por (i) considerarlo visualmente molesto y (ii) porque, en sintonía con los comentarios de Paul Spence sobre el tema, el uso general de la cursiva requiere del esfuerzo del lector para diferenciar entre los diversos tipos de intervenciones editoriales. El objetivo principal en el diseño de un sistema de presentación para las transcripciones expandidas fue estipular una distinción visual entre lo que se presenta directamente en el manuscrito y lo inferido por el editor. Estas y otras intervenciones editoriales están marcadas por el uso de colores diferentes, en lugar de fuentes o tipos de letra.
Los caracteres color negro (o rojo para las rúbricas) sirven para indicar aquellos carateres que están presentes en el manuscrito. Utilizamos una versión atenuada del mismo color para indicar aquellos caracteres inferidos por el editor, generalmente como resultado de la resolución de una marca de abreviatura. Por lo tanto, la apertura del capítulo 4 en el manuscrito Q (folio 2v) lee como sigue:

Donde la tachadura es independiente de otro caracter -como en el caso de un diacrítico sobre vocales- solo el caracter inferido está atenuado. En los casos en los cuales la marca de abreviatura forma parte de otro caracter –como ser ħ, ꝑ y la comilla simple representando ‘er’-, toda la sílaba fue atenuada.
En aquellos casos en los que ha habido intervención del escriba, codificamos con la etiqueta <app> todas las posibles lecturas.

La representación original subyacente es identificada en verde azulado y la lectura enmendada se muestra al situar el puntero del ratón sobre la lectura.
En las transcripciones, las características físicas básicas de la página manuscrita (cambios de columna, cambios de línea, etc.) han sido respetadas, y otras características bibliográficas (iniciales, etc.) han sido marcadas con tamaño y color (aunque no siempre en exacta equivalencia del manuscrito). También se marcan visualmente aquellos pasajes dañados o con lagunas.
Texto crítico
El texto crítico fue preparado utilizando una versión de Peter Robinson’s CollateX desarrollado por Cat Smith y Zeth Green en el Institute of Textual Scholarship and Electronic Editing de la Universidad de Birmingham y puesto en práctica con la ayuda de Peter Robinson de la Universidad de Saskatchewan.
Preparación de los datos
El texto es una hipótesis de la versión primitiva, la cual emplea como texto base aquellas secciones del manuscrito que nos proporcionan la mejor lectura de la primitiva.
La consecuencia de usar solo el testimonio directo de la primitiva para la hipótesis es que la edición termina donde el manuscrito T llega a su fin -el capítulo XX, equivalente al 800 de la PCG-, ya que el texto restante en Estoria Digital (de E2 y Ss) no se deriva directamente de la versión primitiva.
El texto base se compone de la siguiente manera:
E1 : folios 2r-197r, correspondientes a los capítulos 1-574 (PCG cap. 1-565)
E2: folios 2r-17v, los dos cuadernos de E1 posteriormente añadidos a E2, capítulos 574-627 (PCG cap. 566-616)
E2 : folios 18r-21v, correspondientes a los capítulos 628-634 (PCG cap. 617-623)
Y: folios 372v-380vr, correspondientes a los capítulos 635-656 (PCG cap. 624-645)
T: folios 128r-201v, correspondientes a los capítulos 657-811 (PCG cap. 646-800)
Utilizamos el fragmento del manuscrito Y ya que ni E2 ni T poseen testimonio procedente directamente de la primitiva en este punto. El texto resultante es, por lo tanto, una edición “facticia”, compuesta por transcripciones de secciones de distintos manuscritos.
Cada testimonio ha sido cotejado con estas secciones del texto base. El objetivo fue mantener solo aquellas variantes que se consideraron estemáticamente significativas. Por lo tanto, todas las variaciones que fueron consideradas meramente ortográficas fueron regularizadas. Tómese como muestra de ello el siguiente ejemplo con las variantes del manuscrito Q, bloques 16 y 22.
Los topónimos y antropónimos fueron considerados una excepción y no se regularizaron, excepto en los casos de variación gráfica. Las variantes son, por lo tanto, fundamentalmente las que evidencian una alteración en el orden de las palabras, en la forma verbal o en la elección léxica.
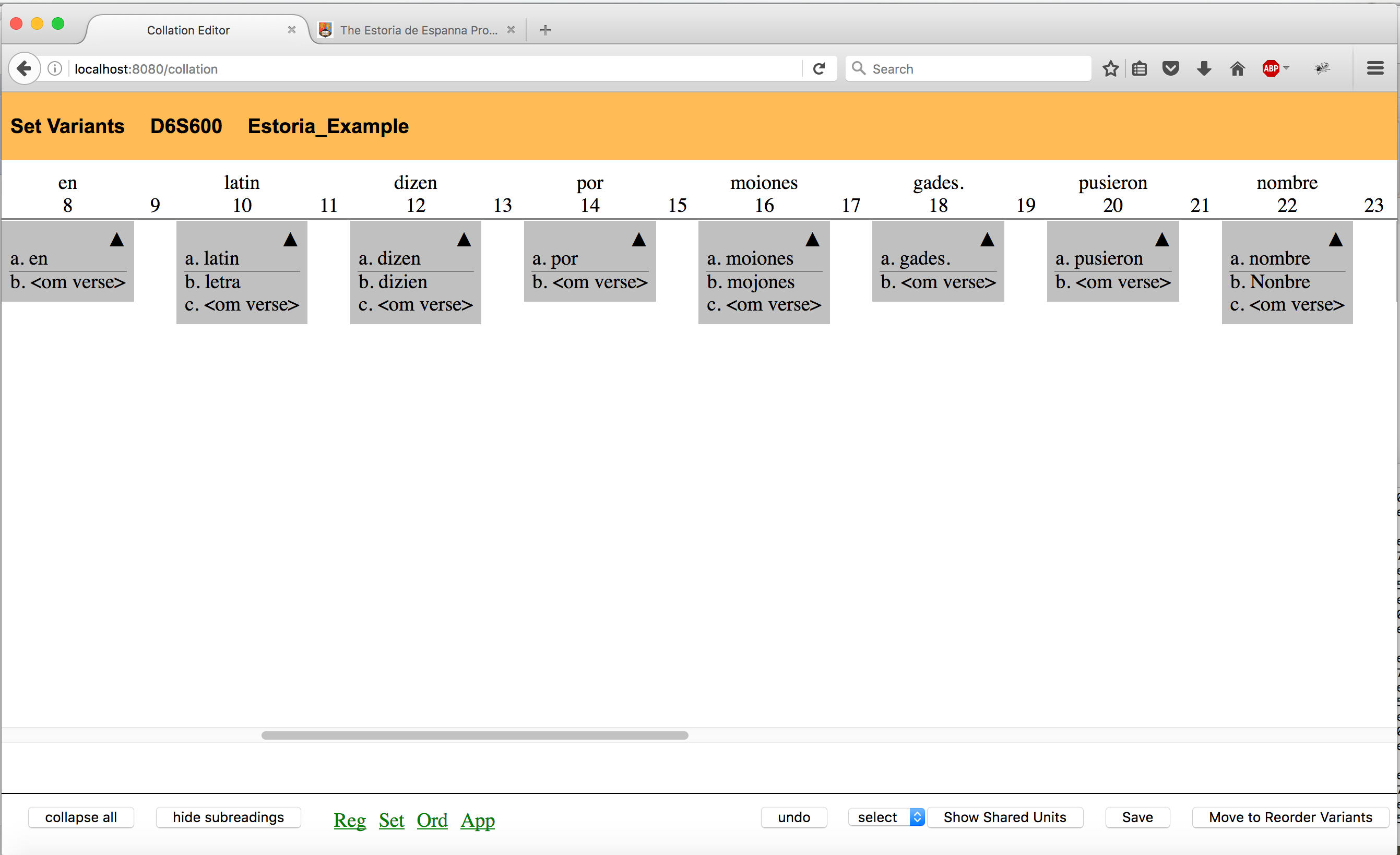
Debido a que el objetivo que se persigue no es enmendar la Estoria, sino mostrarla en toda su diversidad textual, consideramos necesaria la adopción de estos principios conservadores de cotejo. Si es realmente el caso de que, en palabras de David Parker, lo que se busca con esto es la eliminación del “ruido”, no está muy claro que lo que constituya dicho ruido sea lo mismo en todas las ediciones. En el caso de la Estoria, la ausencia de un texto base autorizado con el cual poder cotejar, al menos por ahora, significó la necesidad de ser muy prudentes en la fase de regularización.
Presentación:
La presentación del texto crítico sigue los mismos principios que el de la transcripción: la edición debe aprovechar las herramientas digitales para presentar la Estoria de la manera más amena posible para el lector, sin comprometer la naturaleza del texto. El siguiente es el resultado del cotejo realizado más arriba:
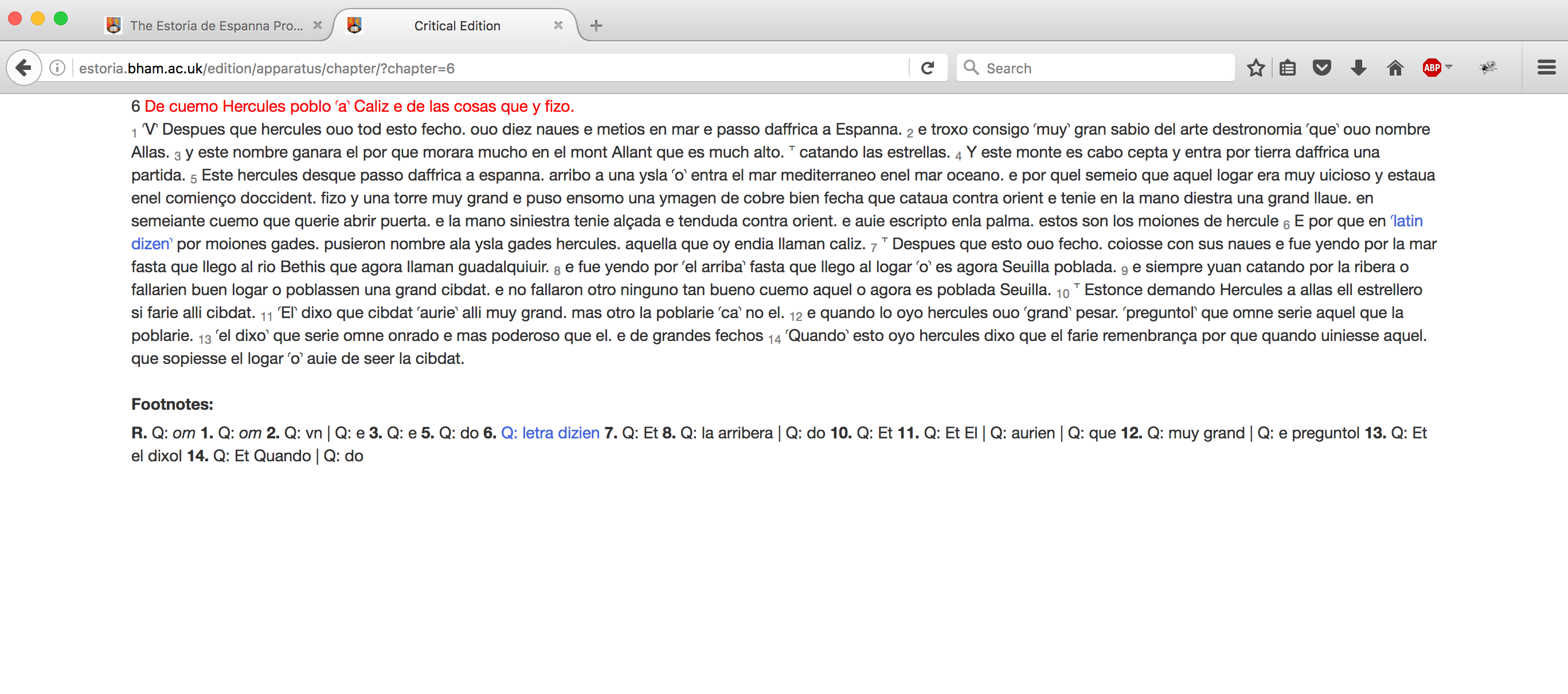
En el texto crítico, ya que la edición no está formalmente vinculada a un único manuscrito, no intentamos imitar la disposición del manuscrito; este se presenta en una sola columna, con notas al pie de página que contienen las variantes. Como decíamos anteriormente, las rúbricas son señaladas en rojo. Hemos intentado reducir, en la medida de lo posible, la acumulación de elementos en la página, de modo que no hemos utilizado las marcas de inserción más allá del tradicional número de la nota al pie. Un movimiento del ratón sobre el texto indicado por las notas altera el color del fragmento en cuestión, y también el de la variante en las notas a pie de página (el bloque 10 del cotejo es resaltado aquí). Atendiendo a la diversidad del texto manuscrito, pero también al carácter necesariamente provisional de la edición, no hemos buscado imponer ninguna regularización sobre el texto crítico; la ortografía y la puntuación siguen las del texto base. Por razones similares, no hemos sustituido las lecturas del texto base con las de otra variante juzgada como mejor; esta es una operación editorial que va más allá de los principios de la presente edición.
Texto de lectura
Para acompañar el texto crítico, y atendiendo a la necesidad de muchos usuarios de una versión puntuada y regularizada de la Estoria, también ofrecemos una versión del mismo texto base de la primitiva, pero sin ninguna variante de lecturas y presentado de tal manera que facilite la lectura a un público moderno. Cabe señalar que, debido a que esta se basa en una transcripción, y no en un texto editado con lecturas preferidas, contiene algunas lecturas del manuscrito que en un texto editado críticamente serían consideradas defectuosas. La totalidad de los criterios utilizados para establecer esta versión regularizada están disponibles aquí.