¡Buenas noticias! Al revisar vuestras transcripciones del Texto 3, es fácil percatarse como continúa la tendencia, ya iniciada en el Texto 2, hacia una mayor precisión en la lectura del manuscrito y en el mejor uso del sistema. Es evidente que cada vez estáis cogiendo más soltura y que ya os cuesta menos tomar ciertas decisiones a la hora de corregir la transcripción base. Por otra parte, os estáis acostumbrado cada vez más a la letra del manuscrito (una gótica libraria bastante regular) y, lo que es más importante, al usus scribendi, tanto por lo que se refiere a las grafías como a las abreviaturas. Esto es muy importante, porque implica superar la presión que ejerce sobre nosotros la transcripción base (sabemos que tenemos que corregirla y nos da cierto temor de no saber distinguir las diferencias), al tiempo que aumentamos nuestra confianza en lo que estamos viendo en la imagen del manuscrito. Ya no nos sorprende tanto encontrarnos con aquellas diferencias gráficas entre E1 y C que al principio nos confundían.
Aquí tenéis una captura de la transcripción del texto en el sistema (versión con y sin expansión de abreviaturas):

Por ejemplo, ya casi no se detectan errores relacionados con el desarrollo de la lineta con valor nasal. ¿Os acordáis? En el Texto 2, y sobre todo en el Texto 1, era frecuente transcribir “i(m)perio” o “e(m)perador”, con <m>, cuando, en realidad, el usus scribendi nos dice que lo más habitual es <n> en este contexto (“inperio”, “enperador”). En el Texto 3 pocas veces ya vemos casos de “te(m)plo” o “no(m)bre”, en vez de “te(n)plo” o “no(n)bre”; los hay, pero muy poquitos. También se ha reducido bastante la presencia de <ñ> (según la ortografía actual) o <nn> (sin abreviar) en las transcripciones, aunque de vez en cuando encontramos casos como: *señor > sen(n)or, *dueña > duen(n)a, *dennasse > den(n)ase.
Fíjate, además, que en este último ejemplo la <ss> doble de E1 (dennasse) aparece <s> simple (dennase) en C, lo cual tiene mucha importancia a nivel gráfico-lingüístico, porque es un ejemplo típico de la indistinción gráfica entre sorda y sonora desde finales del s. XIII en adelante. Esto mismo lo puedes encontrar en otras palabras, en el Texto 3: *buscasse > buscase, *semejasse > semejase, *dizisesseno > diziseyseno, etc. Así que, ¡¡ojo con esta <ss> doble!! La verás mucho en la transcripción base, pero muchas veces aparecerá <s> simple en la imagen (no de manera sistemática, pero sí con relativa frecuencia).
También se ha reducido bastante la confusión entre <v> y <u> en posición inicial: recordad, casi siempre tendremos que corregir <u-> (sistemático en E1) a <v-> (habitual en C). Algunos ejemplos en el Texto 3: *uision > vision, *uezes > vezes, *uez > vez, *uieja > vieja. Sin embargo, donde sí seguimos viendo algunos errores (aunque en menor medida que en los fragmentos anteriores) es en la distinción entre <i>, <j> y <J>: *iudio > judio, *viniesen > vinjesen, *nin > njn, *auino > aujno, *guarida > guarjda, *constantino > constantjno. Recuerda, también, que cuando la <j> tiene trazado alto (<J>) solo la reflejamos en posición inicial de palabra, coincida o no con el valor de mayúscula que le damos en la actualidad (ejs. *judas > Judas, *inojos > Jnojos). Ahora bien, no vayáis a pensar que todos los errores son vuestros, ¡ni mucho menos! Nosotros también nos vamos percatando de las limitaciones o deficiencias de nuestra plataforma digital: como comentaba Aengus hace unos días (Lecciones aprendidas…), la escrupulosidad a la hora de distinguir ciertas grafías como <i, j> no evita, a veces, que la herramienta nos resulte limitada para reflejar esa distinción gráfica en el terreno abreviativo: ¿qué hacemos cuando, como en el Texto 3, las abreviaturas <ihrlm> (Jerusalén) y <ihu> (Jesu-Cristo) aparece con <j> inicial? Es una muy buena pregunta y algunas personas se han dado cuenta muy rápido de este despiste. Bien, de momento, para no sobrecargar la paleta de caracteres especiales, lo dejaremos tal cual como lo tenemos, con <i> (dejaremos constancia de ello en el sistema para poder corregirlo más adelante, tanto en el texto, como en el menú de abreviaturas).
Por supuesto, ya son muy aislados aquellos errores relacionados con la distinción entre mayúscula y minúscula (*mas > Mas) o la confusión en la elección del símbolo abreviativo en la paleta de caracteres especiales (*q(r) ͥ er > q(u) ͥ er), lo que confirma la feliz intuición de que poco a poco os hacéis con el sistema y podéis diferenciar bien los diferentes valores y símbolos de abreviación. Aún así, os indicamos a continuación algunos aspectos nuevos del Texto 3 y también algunos errores puntuales que hemos detectado:
-
-
- Abreviatura NUESTR- y SANCT-: tened cuidado a la hora de insertar esta abreviatura, puesto que ya véis que no incluye el final de la palabra (morfemas de género o número: nuestr-O/A/OS/AS, sanct-O/A/OS/AS). Esto nos evita tener que repetir el símbolo abreviativo en la paleta hasta 8 veces. Cuando la tengáis que insertar, fijaos en hacer bien la selección en el texto base:
-

-
-
- Valores ER y RE: probablemente es el contexto abreviativo más propenso a confusiones, porque no siempre se distingue bien en el manuscrito y a veces lo confundimos con la <e> volada. Solo pondremos dos ejemplos en los que hemos visto mayor confusión: el sustativo “rom(er)ja” y el verbo “p(re)guntando”. En el primer caso, algunas personas se han olvidado de indicar la abreviatura (el ‘superscript hook’, en la 4ª línea de la paleta, 2ª posición). En el segundo caso, algunos transcriptores interpretaron que había una <e> volada, cuando en realidad se trata del mismo símbolo abreviativo de antes (solo que en este caso representa <re>, no <er>) . Veamos, por contraste, un caso real de <e> volada, en la palabra “nonb(r)ᵉ”.
-

-
-
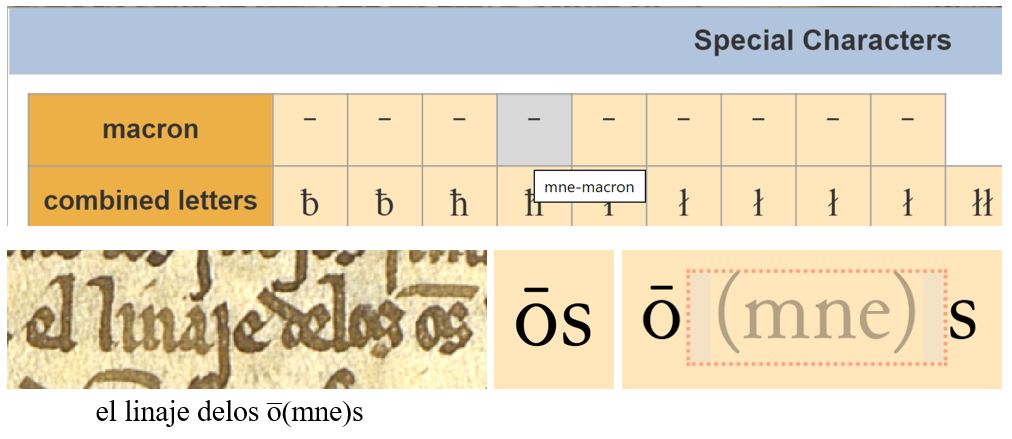
- Abreviatura OS > o(mne)s: es mérito vuestro habernos alertado de la falta de esta abreviatura en la paleta. La tenéis en la primera línea del menú (4ª posición).
-
-
-
- Lineta con valor abrevitivo O y E: *dixo > dix̅(o), *logares > logar̅(e)s. Recuerda que estos valores, menos frecuentes, de la lineta los puedes encontrar en la paleta de caracteres especiales en la primera línea hacia al final (7ª y 8ª posición).
- Símbolo US: *uenus > uen9(us). Recuerda que este símbolo se parece al número 9 y que tiene el valor de <us> o <con> (ej. confirmar). Lo encuentras en la paleta en la 4ª línea hacia el final (antes de la <ç> cedilla).
- Lineta con valor <ua> vs. vocal volada <a>: a veces es fácil confundirse entre uno y otro símbolo cuando el valor abreviativo es el mismo, en este caso la secuencia <ua>. En el Texto 2 veíamos algún caso de “qual” abreviado con lineta: q̄(ua)l (“qual conuenie”). Algunas personas pensaron, con buen criterio, que se trataba de la secuencia “quel” (q+ lineta = <que> + el artículo el o el pronombre le abreviado), pero en realidad era el valor <ua> abreviado, aunque con menos frecuencia, con la lineta. Esto nos obliga a estar atento siempre al contexto y contenido del texto, para acertar con la interpretación correcta de la abreviatura. En cualquier caso, en el Texto 3, nos encontramos con que la secuencia <ua> está abreviada con la <a> volada, algo mucho más frecuente que con la lineta: q(u)ªl. Aquí podéis ver la diferencia tanto paleográfica como en la transcripción
-

-
-
- Abreviatura de CRISTO, CRIST-, ORAÇION: ya sabéis que en el menú de abreviaturas tenemos dos opciones para la abreviatura de ‘cristo’: xp̅o y xº. Os habréis fijado que en el Texto 3 tenéis que usar esta última opción (xº). En cuanto a la forma “cristianos”, ya incluimos en la paleta de caracteres especiales la opción <x ͥ >, que representa “crist-” + la <i> volada, que debemos mantener en la transcripción (a diferencia de cuando la <i> volada abrevia <u> o <r>: q(u) ͥ so, p(r) ͥ mero, en “x ͥ (crist)ianos” la <i> volada se sitúa antes del valor abreviativo, así que hace falta mantener la <i> después de dicho valor). Por último, en el fragmento b del Texto 3, al principio de la línea 12, aparece la forma “or̅on” abreviada: ¿ya sabéis lo que significa, verdad?
-

-
-
- Otros errores de transcripción detectados: *benedito > bendito, *uj tercera > iijª (puedes poner la ª directamente desde el teclado) *cruçifigado > cruçificado, *fazon > sazon (confusión de <s> alta por <f>), *razon > rrazon (en C lo más frecuente que es que la <r> inicial sea doble), *ell > el, *alli > ally, *misma > mesma, *dizisesseno > diziseyseno.
-
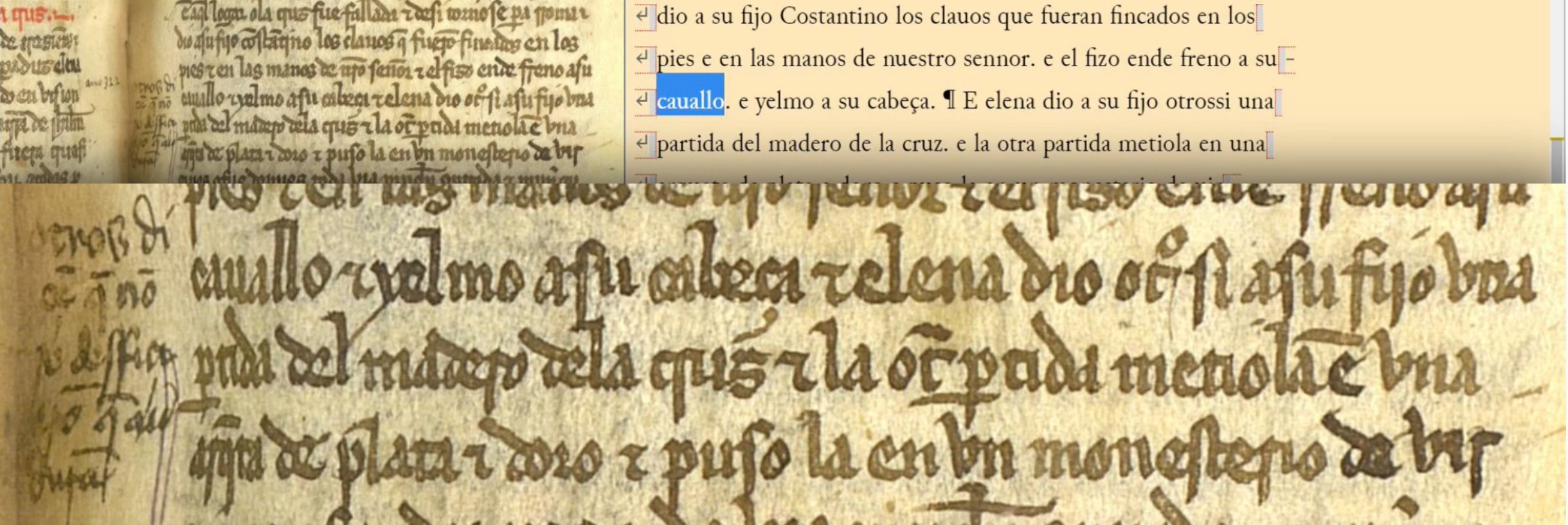
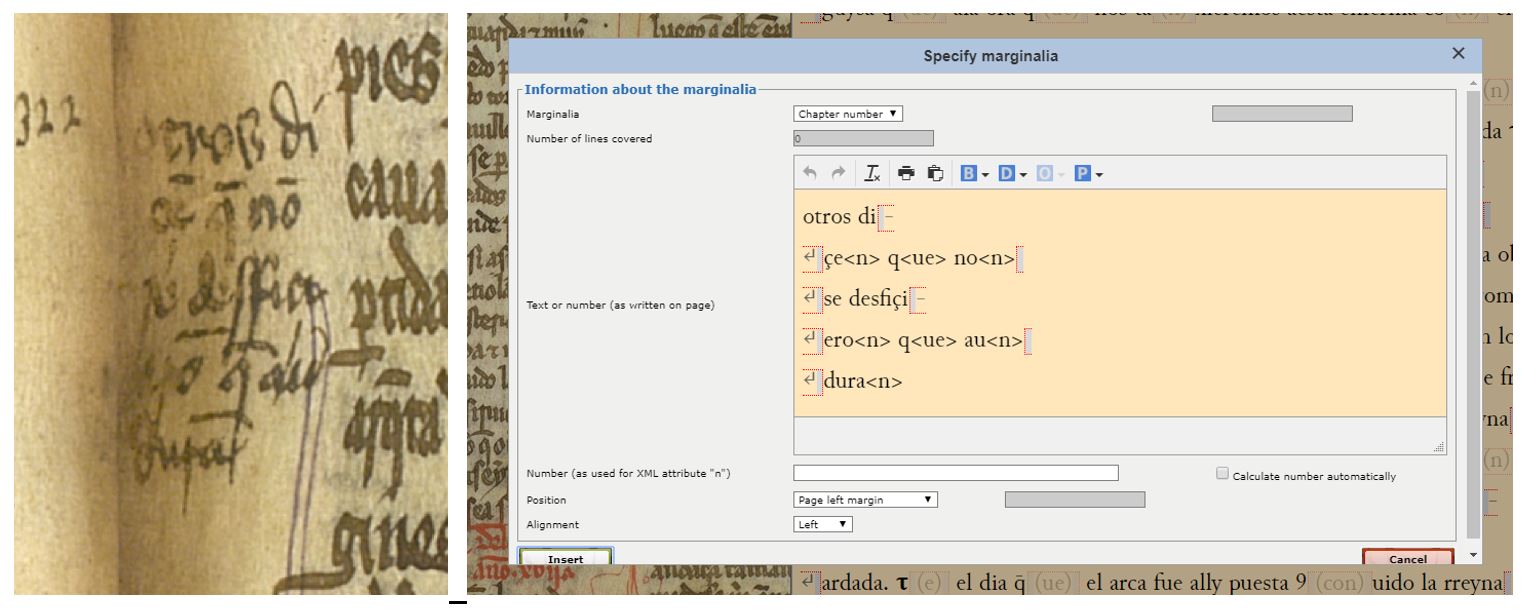
Acabamos este repaso de las transcripciones del Texto 3, recordando cómo etiquetar la marginalia y algunas intervenciones correctivas del copista/lector. En cuanto a lo primero, hace unos días comentábamos en las redes sociales cómo interpretar la nota marginal y cómo etiquetarla en el sistema. Parece que la lectura correcta es: “Otros diçen que non se desfiçieron; que aun dura”, y hace referencia al pasaje en cuestión, sobre cómo Elena partió el madero de la Vera Cruz en dos partes (una se la dio a su hijo y otra la metió en una arqueta de plata y de oro y la guardó en un monasterio). El lector del texto nos informa de que en otras fuentes (“otros”) se habla de que el madero realmente no se llegó a partir y que aún se conserva íntegro. Para incorporar esta nota en el sistema tenemos que usar el menú Marginalia (podéis situar el cursor justo antes de la palabra “cauallo”, con la que comienza la línea 27 de esa columna, en la misma altura en la que se encuentra la nota en el margen). Como de momento no podemos introducir abreviaturas en el menú Marginalia, las hemos representado entre ángulos (< >), pero no hace falta que vosotros las pongáis en vuestras transcripciones:
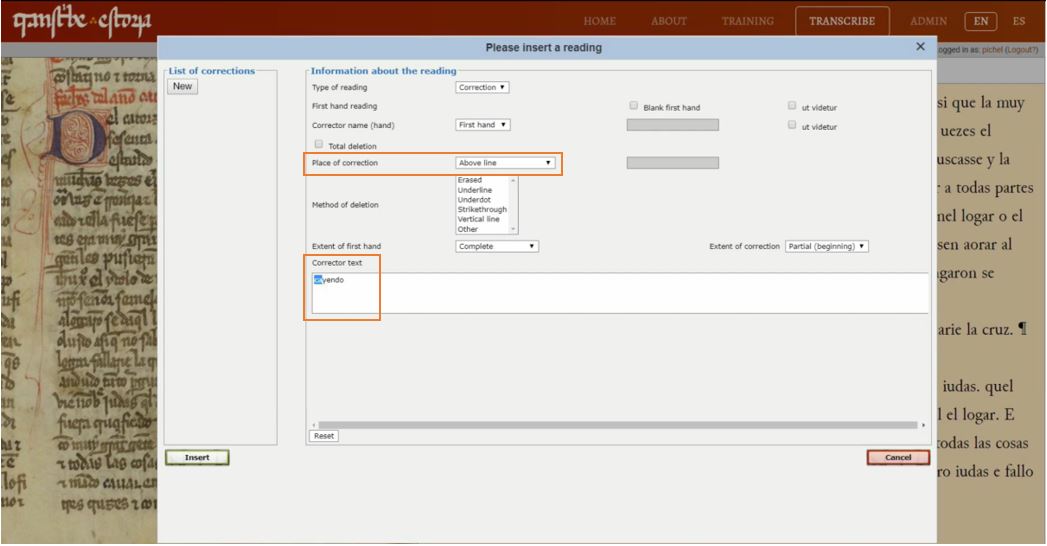
Por otra parte, en el Texto 3 vemos, al menos, dos intervenciones correctivas del copista o del revisor/lector. Ya las hemos comentado en el Módulo 4 del material de capacitación, pero lo recordamos aquí. En el primer fragmento vemos que en la palabra “cayendo” la primera sílaba aparece añadida en el interlineado. Esto hay que indicarlo en el sistema a través del menú Corrección: como ya os hemos dicho en otras ocasiones, no os preocupéis por rellenar más que dos campos: lugar de corrección (‘place of correction’), en este caso ‘above line’, y la indicación del propio texto corregido (en el cuadro ‘corrector text’). Como veis en la imagen, tan solo hace falta que escribáis la palabra corregida (“cayendo”) para que el sistema grabe esa información.

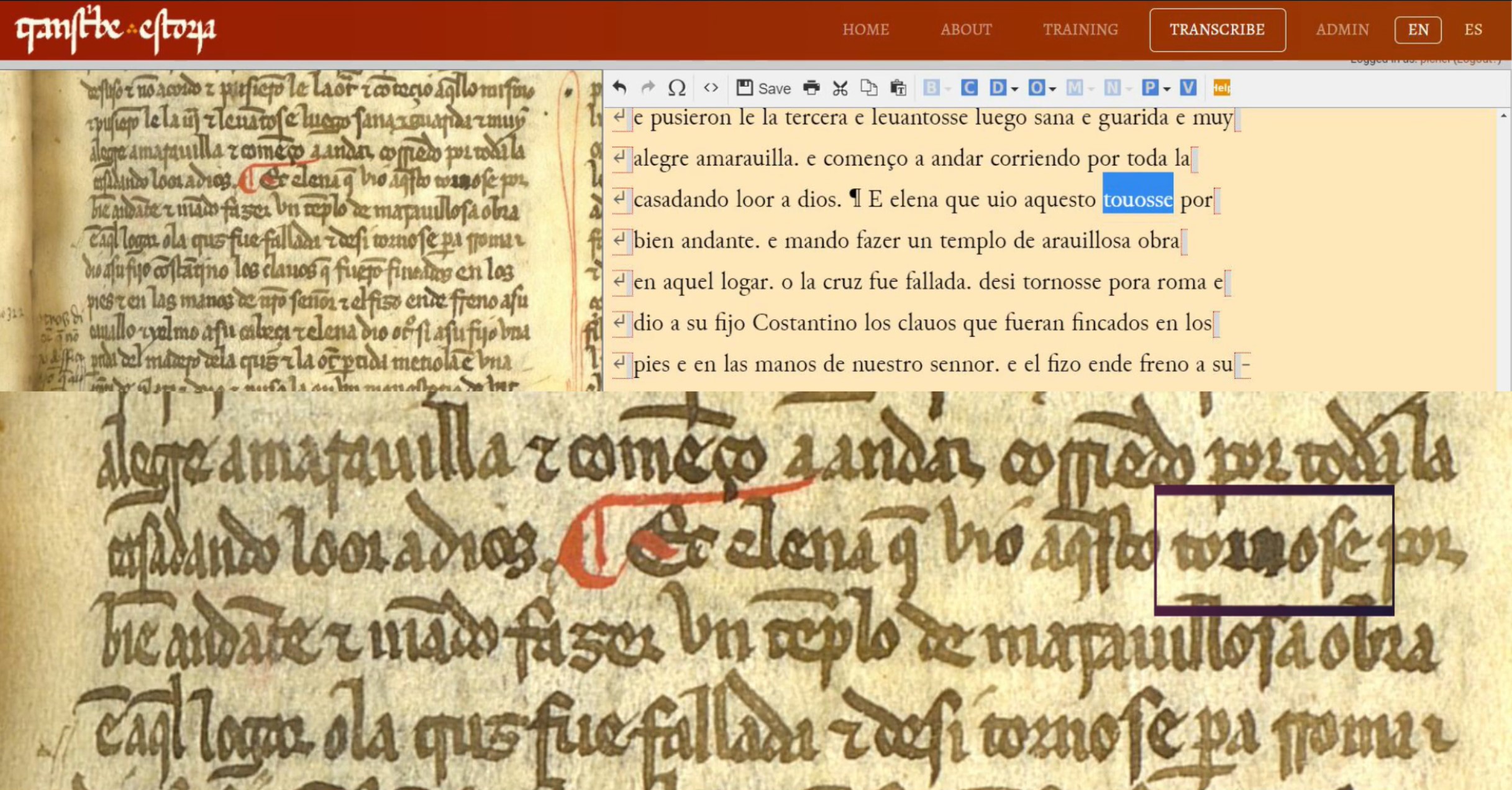
En el segundo fragmento del Texto 3, vemos otra intervención en la palabra “tornose”, que parece que sufrió algún tipo de corrección en las letras <r> y <n>. Y es muy posible que así fuera, porque si nos fijamos en el texto base, leemos en el mismo lugar “touosse” (‘se tuvo por bienandante, se sintió afortunada’). Es posible, entonces, que el copista se diera cuenta del error e intentanse enmendar la secuencia <rn> por una <u>: “tornose” > “touose”. Fuera como fuese, ante la sospecha, lo indicaremos nuevamente en el menú Corrección, señalando tanto la forma presuntamente errada como la corregida. Opcionalmente también puedes indicar dónde y cómo se produce la corrección (en este caso pondremos ‘overwritten texto’, es decir, texto sobrescrito).

¡Lo dejamos por hoy! Espero que la lectura de este post haya sido útil e interesante. Volveremos a la carga en los próximos días con nuevas entradas en nuestro blog, así que ¡no te lo pierdas! y coméntanos por aquí, en las redes sociales o por correo, cualquier duda que tengas. Ya sabes que estamos a tu plena disposición.
Ricardo, Polly y Aengus.