We have revised your transcriptions of Text 4 and we can confirm that the level of precision is yet again even higher. Great stuff! We sincerely congratulate you for your perseverance and interest in contributing to this project. Before we begin our feedback, here you have a screenshot of the transcription, with and without expansions. Have a little look:

The errors regarding *c > ç, *i > j, *u > v are now very occasional, although from time to time a word might slip through the cracks: *uino > vino, *un > vn, *uos > vos, *uilla > villa; *inperio > jnperio, *nin > *njn, *coraxinos > coraxjnos; *cinco > çinco, *conoscido > conosçido. Linked to these last two examples (*c > ç), you will have realised that usually the letters <sc> (E1) are simplified in ms. C, where they tend to appear as <ç> or <c>; this is a mistake we are repeatedly seeing in your transcriptions: *seyscientos > seyçientos, *nasciera > naciera. Of course, as with everything, this rule is sometimes broken, such as in the case of “conosçido”. Don’t forget to look out for these small details, because they are important for the history of writing in Castilian, and of the language itself.

Look out also for word-spacing: the union or separation of words, as often we see errors such as *vinose > vino se, atodos > a todos, *sinon > si non, *salio se > saliose. We have found only a few errors with capitals/lower-case letters, and these tend to be one-offs: *annos > Annos y *Mahomad > mahomad.
Pay attention also to the letters which may change from one manuscript to another: *vozes > bozes (in E1 it appears with a <u>: uozes), *mahomat > mahomad (in the rubric), *estonçes > *entonçes. The distinction *ss > s we have discussed previously: *subiesse > subiese, *fuesse > fuese.
Regarding the confusion between the representation of nasal consonants, *ñ > n(n) y *m > n (at the end of a syllable before <p> and <b>), only in a few cases have we spotted errors such as *señaladamente > sen(n)aladamente, *co(m)panna > co(n)panna. Have you looked closely at this last example? Have you noticed anything strange when transcribing the word “conpanna”? You probably have: in the base text (E1) the word “campana” appeared, but in C the scribe mistook this for “conpanna” (‘compaña, compañía’, company), which makes no sense in the context: “Despues desto mando Mahomat que subiesse un moro en las torres o las campanas de los cristianos solien estar” (E1) > “despues desto mando mahomad que subiese vn moro en las torres olas conpannas delos cristianos solien estar” (Translation of E1: “Following this, Muhammad ordered that a moor should go up to the towers where the bells of Christians used to be”). The passage refers to the Christians’ campanas – their bells, which were usually in the towers (the word “o” < lat. UBI means ‘donde’, or ‘where’: las torres donde las campanas solían estar, the towers where the bells used to be). Notice also that at the end of the same line as where “conpanna” appears, we find the word written correctly – “canpana”.

As well as the confusion over campaña/campana, justified by the almost identical sounds in the two words, you have surely also seen some other differences between ms. C and the base text. For example, the involuntary repetition of the phrase in line 11 of the first fragment: “non osaua el andar por la villa njn osaua el andar”. Of course, you should reflect this repetition in your transcription.

Just after this, at the start of the following line, in ms. C. the adverb “muy” is omitted in the sequence “si non [muy] encubierta mente e muy omildoso”: you should, of course, delete it from your transcription. Further on, in the sequence “por venir ala oraçion”, you will have spotted that in the base text we find “pora”, whilst the scribe of C copies it as “por”. At the start of the rubric (title) of the chapter, don’t forget that you should add the chapter number that C gives: “Capitulo Ciº”. Some people can put in the º (‘primero’) directly from their keyboard.
Finally, there is an error in C that only a few people managed to identify and indicate in the transcription: “e atodos los que del su linaje eran desi començolos de su palabrar e dixo les”. The form has an erroneous <-r> at the end (the scribe should have written palabra, as in the base text). The word is divided by the line-break, which perhaps contributed to the scribe’s confusion.

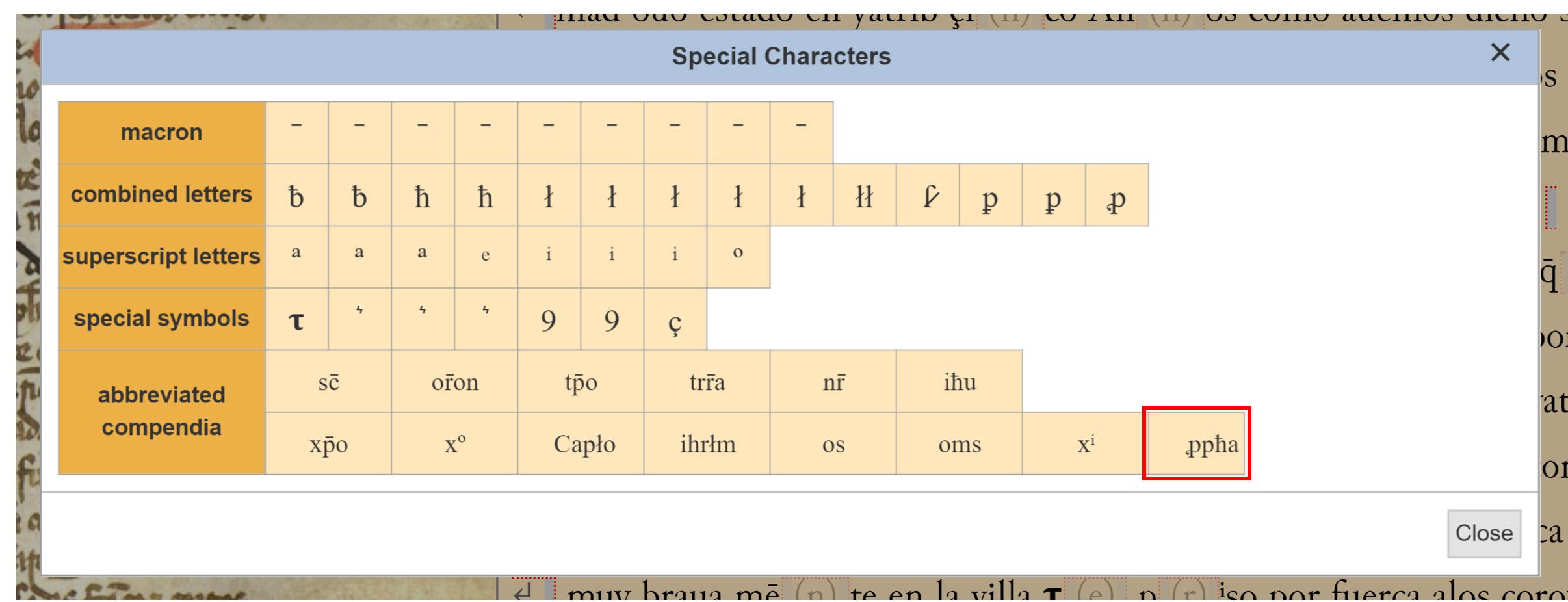
We will finish this feedback by looking at the topic of abbreviations. We know you love them :-p ! As we have already mentioned to you by email and on social media, the abbreviation of “p(ro)ph(et)a“, is now available in the special character palette. Thanks for noticing it was missing!
The word “siempre” (of course, an exception to the rule, since it has an <m> before the <p>, in contrast with the habitual <np>) is abbreviated in the last syllable, with a superscript <e>, whilst the symbol represents <re>: *siemp(r)ᵉ > siemp ͛ (re). You know that this same abbreviating symbol (the superscript hook) can represent other values, such as <er> (fazer) or <ir> (dezir); both of which also appear in Text 4.

Remember that the symbol ‘9’ usually has the value of <us> (or sometimes <con>: there was one person who did not read the possessive correctly ‘sus‘ and wrote ‘*so’. Remember also that in the abbreviation “xⁱanos” you should include the letter <i> after the abbreviation: xⁱ(crist)ianos (the <i> is not really abbreviated, so is not contained in the parentheses – it is part of the symbol, but not its abbreviative value). One last issue: the abbreviated sequence “en(e)l” can be transcribed in two ways: using the macron independently or combined with the letter <l>. In this case, as the macron in the manuscript covers the whole word, including the <l>, you can opt for either of the solutions:

Once more: thank you very much for your collaboration, and good luck with text 5, and if you choose to, with the other folios of the manuscript that we have been uploading to the platform. Onward we go!
Ricardo, Polly and Aengus.