Hemos revisado vuestra transcripción del Texto 4 y comprobamos, nuevamente, que el nivel de precisión cada vez es más elevado. ¡¡Enhorabuena!! Os felicitamos sinceramente por vuestra perseverancia e interés en contribuir al proyecto. Antes de nada, aquí tenéis una captura de la transcripción, con y sin expansiones: ¡¡échale un par (de ojos)!!

Los errores del tipo *c > ç, *i > j, *u > v son ya bastante ocasionales, aunque de vez en cuando se os escapa alguna palabra: *uino > vino, *un > vn, *uos > vos, *uilla > villa; *inperio > jnperio, *nin > *njn, *coraxinos > coraxjnos; *cinco > çinco, *conoscido > conosçido. Relacionado con estos últimos dos ejemplos (*c > ç), te habrás dado cuenta de que normalmente la grafía <sc> (E1) se simplifica en el ms. C, donde aparece normalmente <ç> o <c>; este sí que ha sido un error repetido en vuestras transcripciones: *seyscientos > seyçientos, *nasciera > naciera. Por supuesto, como en todo, esta regla no siempre se cumple, como en el caso de “conosçido”. No dejes de fijarte en estos pequeños detalles, porque son importantes para la historia de la escritura y de la lengua.

Ojo también con la unión y separación de palabras, que a veces se os escapan errores como: *vinose > vino se, atodos > a todos, *sinon > si non, *salio se > saliose. Errores de mayúsculas/minúsculas apenas hemos encontrado, únicamente, de manera muy puntual: *annos > Annos y *Mahomad > mahomad.
Presta atención, también, a algunas grafías que cambian entre uno y otro manuscrito: *vozes > bozes (en E1 aparece con <u>: uozes), *mahomat > mahomad (en la rúbrica), *estonçes > *entonçes. La distinción *ss > s ya la hemos comentado otras veces: *subiesse > subiese, *fuesse > fuese.
En cuanto a la confusión en la representación de las consonantes nasales *ñ > n(n) y *m > n (a final de sílaba antes de <p> y <b>), solo en algún caso hemos detectado errores como: *señaladamente > sen(n)aladamente, *co(m)panna > co(n)panna. Por cierto, ¿os habéis fijado en este último ejemplo? ¿Habéis notado algo extraño al transcribir la palabra “conpanna”? Seguro que sí: en el texto base (E1) aparececía “campana”, pero en C el copista se confundió por “conpanna” (‘compaña, compañía’), que no tiene sentido en el contexto: “Despues desto mando Mahomat que subiesse un moro en las torres o las campanas de los cristianos solien estar” (E1) > “despues desto mando mahomad que subiese vn moro en las torres olas conpannas delos cristianos solien estar”. El pasaje se refiere a las campanas de los cristianos, que solían estar en las torres (por cierto, la palabra “o” < lat. UBI significa ‘donde’: las torres donde las campanas solían estar). Fíjate, también, que al final de la misma línea donde aparece “conpanna” se escribe, esta vez correctamente “canpana”.

Además de esta confusión campaña/campana, justificable por la casi absoluta identidad fónica entre las dos palabras, seguro que has notado algunos otros cambios en el ms. C con respecto al texto base. Por ejemplo, la la repetición involuntaria de una frase en la l. 11 del primer fragmento: “non osaua el andar por la villa njn osaua el andar”. Por supuesto, esta repetición debes reflejarla en la transcripción.

Justo después, al comienzo de la siguiente línea, el ms. C omite el adverbio “muy” en la secuencia “si non [muy] encubierta mente e muy omildoso”: claro está, debes eliminarlo de tu transcripción. Más adelante, en la secuencia “por venir ala oraçion”, te habrás fijado que en el texto base aparecería “pora”, mientras que en C se copia “por”. Al comienzo de la rúbrica (título) del capítulo, no te olvides, debes hacer constar el número del capítulo que añade el ms. C: “Capitulo Ciº”. El º (‘primero’) puedes ponerlo directamente desde tu teclado.
Hay, por último, un error en C que pocas personas lograron identificar e indicar en la transcripción: “e atodos los que del su linaje eran desi començolos de su palabrar e dixo les”. La forma resaltada, en efecto, tiene una <-r> final por error (debería poner palabra, como en el texto base). La forma está translineada (pa-labrar), lo que quizás contribuyó a la confusión por parte del copista.

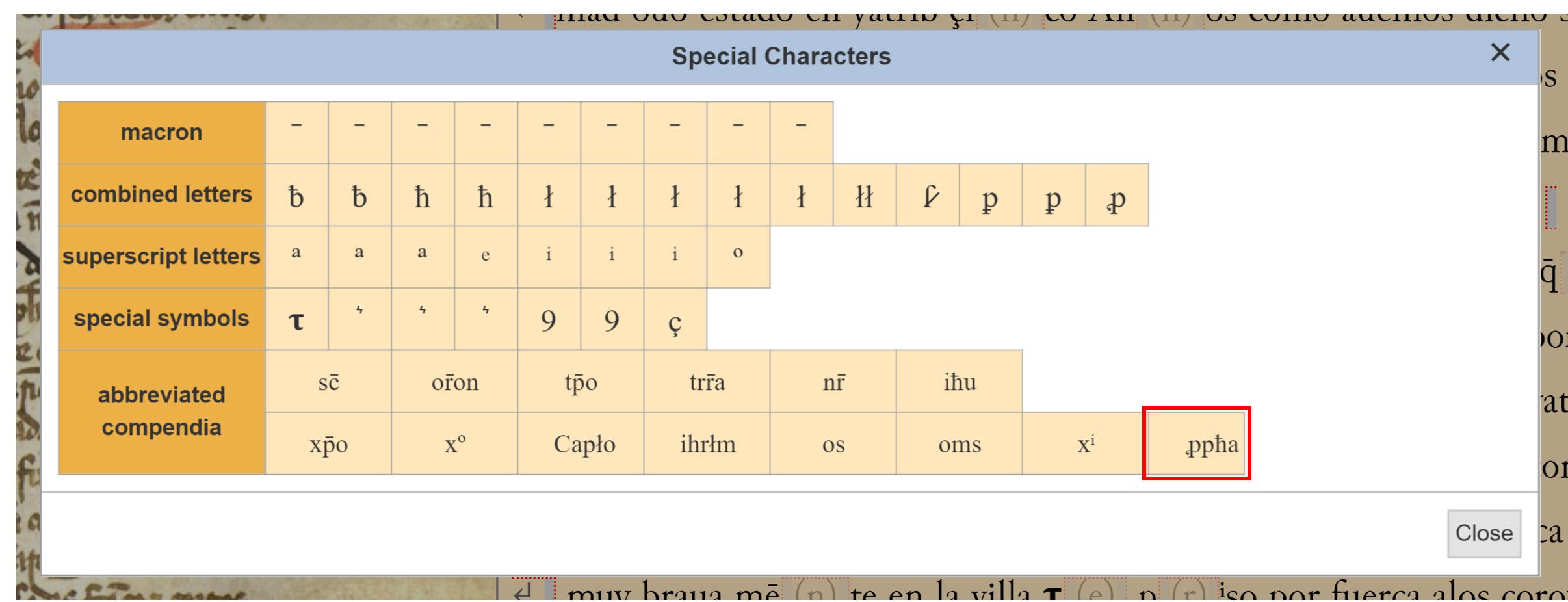
Terminamos este repaso, hablando de abreviaturas. ¡¡Sabemos que te encantan!! Así que no disimules tu impaciencia :-p Por una parte, como ya hemos comentado con vosotros por correo y en las redes sociales, está la abreviatura de “p(ro)ph(et)a“, ya disponible en la paleta de caracteres especiales. ¡Gracias otra vez por el aviso!
La palabra “siempre” (por cierto, una excepción a la regla, pues presenta <m> ante <p>, contra lo habitual: <np>) está abreviada en la última sílaba, pero con la vocal volada <e>, sino con el símbolo que representa <re>: *siemp(r)ᵉ > siemp ͛ (re). Ya sabes, por cierto, que este mismo símbolo abreviativo (el ‘superscript hook’) puede representar otros valores como <er> (fazer) o <ir> (dezir); ambos aparece también en el Texto 4.

Recuerda que el símbolo ‘9’ tiene normalmente el valor de <us> (a veces también <con>): hubo alguna persona que no leyó bien el posesivo ‘sus‘ (*so). Recuerda también que la abreviatura “xⁱanos” debes incluir también la letra <i> tras la abreviatura: xⁱ(crist)ianos (la <i> no está realmente abreviada, y por eso no está entre paréntesis; es parte del símbolo, pero no del valor abreviativo). Y una última cuestión: la secuencia abreviada “en(e)l” puedes indicarla de dos maneras: usando la lineta independiente o combinada con la letra <l>. Como en este caso la lineta abarca toda la palabra, incluyendo la la <l>, puedes optar por cualquiera de las dos soluciones:

Una vez más: muchas gracias por tu colaboración y mucho ánimo con el texto 5 y, si es el caso, con los restantes folios del manuscrito que vamos subiendo a la plataforma. ¡Seguimos!
Ricardo, Polly y Aengus.
Ya que estamos casi al final de esta experiencia, me gustaría agradecer a todo el equipo todas las explicaciones y, en definitiva, todo el apoyo y la atención que nos ofrecéis. Muchas gracias y enhorabuena por el proyecto.
Los comentarios que elaboráis tras las transcripciones son muy útiles y de gran ayuda.
Gracias a ti Paula. ¡Esperamos verte en transcribeestoria 2.0!