Esta semana nos encontramos en el ecuador de nuestro experimento piloto Transcribeestoria, así que pensamos que podría ser un buen momento para reflexionar sobre lo que hemos estado haciendo hasta ahora, con el objetivo de responder algunas preguntas que han surgido en las últimas semanas, aclarar otras cuestiones acerca de la postura ética mantenida en el ámbito del trabajo colaborativo (crowdsourcing), y también para contaros un poco más sobre lo que nos gustaría hacer en el futuro.
Probablemente estés aburrido de escucharnos decir que (i) este es un proyecto piloto y que (ii) estamos muy agradecidos por tu aportación. ¡¡Todo esto es cierto, a pesar de tanta repetición!! El objetivo del proyecto es, ante todo, comprobar si existe un interés público por la cultura manuscrita medieval. El hecho de que hayamos alcanzado las 300 inscripciones parece confirmar que, efectivamente, existe ese interés, lo que nos ayudará a desarrollar los proyectos planificados para los próximos años y nos compromete, además, a continuar con este método de trabajo colaborativo de una u otra forma. Los restantes objetivos de esta iniciativa pasaban por la creación de una serie de materiales de capacitación y entrenamiento que permitieran desmitificar los manuscritos medievales y, en consecuencia, que animaran a las personas no especialistas a acceder y trabajar con las imágenes de los materiales originales y, eventualmente, involucrar a un público más amplio en la compilación y desarrollo de nuestros materiales de investigación. El número de usuarios de nuestro canal de Youtube sugiere la consecución del primer objetivo, pero para lograr el segundo aún queda un largo camino que recorrer.
Hemos aprendido mucho con todos vosotros en estas cinco semanas. Gracias a vuestra transcripción, hemos podido detectar varias deficiencias técnicas en el sistema. En particular, ha sido especialmente útil el aviso que nos habéis trasladado sobre la ausencia de ciertos caracteres importantes en el menú de abreviaturas. Entre otros, por ejemplo, hemos agregado recientemente la opción x ͥ > “crist”, o la <ç> cedilla pensando en aquellas personas cuyos teclados no tienen acceso directo a esta grafía. Lo cierto es que siempre hay una compensación, por un lado, entre el deseo de representar lo máximo posible la materialidad escrita, y por otro, la capacidad técnica para hacerlo.
A veces resulta irónico, pues a pesar de la intensa y necesaria discusión sobre, por ejemplo, la necesidad de distinguir entre <i> y <j>, resulta que la expansión ihrłm > ierusalem solo es posible con <i>. Este tipo de lecciones serán muy útiles, sin duda, para futuros desarrollos del proyecto.

Ups…!
¿¡¿¡¿A dónde van nuestras transcripciones?!?!?
Si estás interesado en lo que hacemos con tus transcripciones, te daré una pequeña pista. De primero, utilizamos las transcripciones que nos proporcionas para que podamos ver cómo se comporta el sistema. Todos los pasajes fueron transcritos también por nosotros mismos, por lo que comparamos su salida XML con nuestras propias versiones corregidas para detectar dónde se están cometiendo errores o qué opciones del sistema presentan más dificultad. A partir de esta comparación, Polly y Ricardo extraen y jerarquizan los errores o dificultades más comunes, que es la base de nuestras publicaciones de la semanas 2 y 4, en las que os comentábamos cómo vais progresando en vuestras transcripciones. Como ya hemos dicho anteriormente, lo cierto es que no supimos anticipar el éxito de inscripción en el proyecto, por lo que no hemos podido comentar de manera individual vuestro progreso, pero ahora sí lo podemos anticipar en un futuro a medida que el proyecto se desarrolle. Nuestro taller digital de transcripción ofrece la posibilidad de contar con un texto corregido que permite hacer la comparación automática con la transcripción del usuario y que proporciona comentarios instantáneos. Como estamos en fase piloto, de momento esta función no está del todo desarrollada, pero sin duda será uno de los aspectos más importantes a integrar en una versión más completa del sistema. Esta mejora permitiría que cada transcriptor pudiera tener acceso a un feedback individual. Por supuesto, esto requeriría de la preexistencia de una versión correcta de la transcripción, algo que no es especialmente problemático.
El objetivo principal del proyecto actual es acoger a un grupo más amplio de personas interesadas en la cultura manuscrita medieval, desmitificando, así, los bellos objetos con los que trabajamos, haciéndolos más accesibles e inteligibles. De momento, estamos probando el sistema utilizando solo cinco breves pasajes del manuscrito C, pero el resto del códice aún está por transcribir. A mediados de noviembre, colgaremos en la plataforma los primeros 25 folios del manuscrito. Si te animas a seguir transcribiendo, el XML resultante podrá en algún momento incorporarse a la edición digital de la Estoria de Espanna. El objetivo secundario de Transcribeestoria es ver si contamos con un grupo suficiente de personas interesadas en la siguiente etapa, esto es, en participar en la investigación original sobre la Estoria de Espanna ayudándonos a transcribir los manuscritos que aún no están incluidos en la edición.
Los archivos XML generados a partir de vuestras transcripciones serán muy útiles para nuestra investigación, pero no podemos incorporarlos directamente a la edición. Aquí tienes un ejemplo del formato de salida de una de las transcripciones más recientes:

El texto transcrito se guarda en formato XML. Se trata de un lenguaje de marcado diseñado para ser legible tanto por los seres humanos como por las computadoras. Los proyectos de humanidades digitales usan habitualmente una versión o subtipo (dialecto, si se prefiere) de este lenguaje, llamado TEI (Text Encoding Inititive). La idea básica es que toda la información relevante para la investigación se enmarca entre dos etiquetas (una de inicio y otra de cierre): así, por ejemplo cuando marcas en la transcripción que la <q> presenta una lineta por encima de la letra, aparece en el XML como q<am>̄</am><ex>ue</ex>, secuencia en la que todo aquello que aparezca entre <ex> y </ex> representa el valor abreviativo expandido. Aunque puede resultar un poco difícil al principio, en realidad es un sistema de marcación sumamente lógico.
Todas nuestras transcripciones se guardan en XML compatible con TEI5 (aunque de momento estamos trabajando con una versión XML-TEI simplificada con respecto a la utilizada en Estoria de Espanna Digital). Pero, afortunadamente para ti, Transcribeestoria es un sistema wysiwyg (What You See Is What You Get; en español “lo que ves es lo que obtienes”), creado por Cerys y el equipo BEAR aquí en la Universidad de Birmingham, quienes diseñaron un sistema que te permite escribir lo que ves al tiempo que en segundo plano, de manera silenciosa, los cambios se graban en lenguaje XML, que es lo que luego usamos para nuestra investigación.
Como pudiste ver en la imagen anterior, la codificación que hay detrás de la transcripción es muy detallada, discriminando también las palabras individualizadas entre espacios, que aparecen enmarcadas en las etiquetas <w> </w>. La siguiente imagen es el archivo XML del mismo pasaje en E1 extraído de nuestra edición. Como verás, hay algunas diferencias:
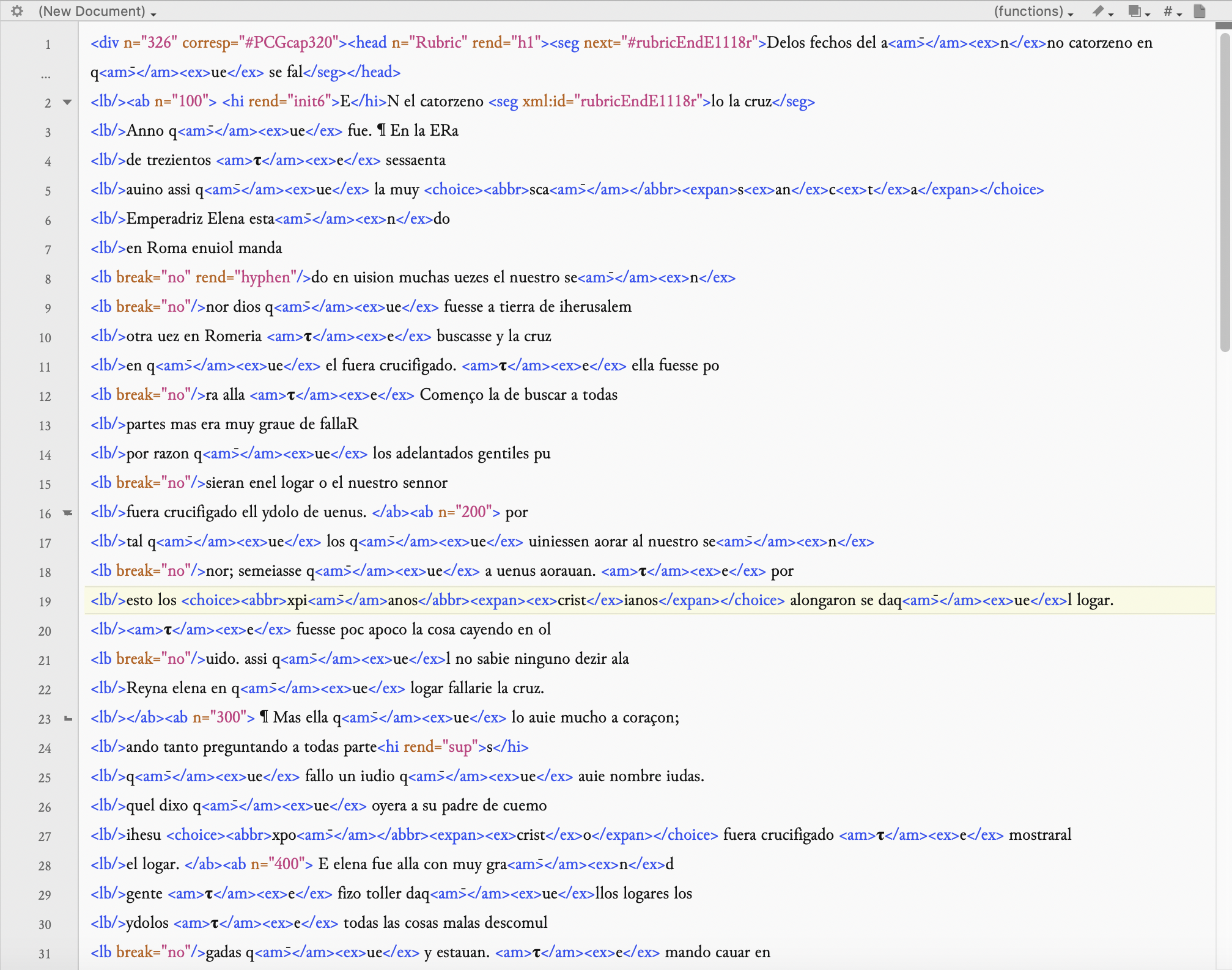
La diferencia más obvia (además de la ausencia de etiquetas <w>) es la presencia de números en el texto de la edición. Estos números nos dicen, por ejemplo, en qué capítulos nos encontramos (ej. el capítulo 326 de la edición aparece como <div n = “326”>); también nos informan de cada uno de los enunciados del capítulo. Hemos enumerado todos los enunciados de la crónica (puedes verlos en la edición), porque esto genera una forma estándar de referirse a cualquier parte del texto, con independencia del manuscrito a partir del cual se lea. Así, por ejemplo, al buscar 326.2 en cualquier manuscrito, obtendrás el mismo enunciado en los diferentes testimonios transcritos, en este caso, la secuencia que comienza “por tal que los que uiniessen aorar al nuestro senor”. Esto permite cotejar todos los testimonios de la Estoria, con lo que se reúne en un único “lugar” digital la compilación y comparación de todas los materiales relacionados con la obra. En el caso de que te animes a proseguir con la transcripción por tu cuenta (¡y ojalá así sea!), tendríamos que agregar todos los números después, porque la plataforma que actualmente estamos usando no permite incluir estos números (será mejor no aburrirte contándote los motivos…).
Crowdsourcing: ¿investigación gratuita en tiempos de economía de bolos?
En una interesante publicación en nuestro blog hace unas semanas, Polly reflexionaba sobre la justificación del crowdsourcing. Comprendo que haya cierta inquietud, especialmente en la comunidad investigadora de España, y en particular entre los investigadores noveles y/o postdoctorados, relacionada con la base ética de lo que estamos haciendo. Todos hemos escuchado historias de terror sobre el trabajo preliminar llevado a cabo por investigadores primerizos cuando se incorporan a los grandes trabajos de investigación sin que ello se traduzca en un reconocimiento público. En primer lugar, me gustaría señalar que toda la labor de transcripción realizada por voluntarios colaboradores en el proyecto original de Estoria de Espanna Digital se reconoció adecuadamente en los créditos de esa edición. Si estuviéramos en condiciones de incorporar también ahora cualquiera de vuestras transcripciones (algo que, como se mencionó antes, aún está lejos ocurrir), volveríamos a hacer exactamente lo mismo. Pero nuestro principal objetivo es ampliar el conocimiento y la comprensión más allá de las comunidades académicas. Tenemos planes provisionales para acercarnos, por ejemplo, a los Centros de mayores en el futuro, para ver si allí hay también algún interés en participar. Al mismo tiempo, sería ingenuo fingir que no hay un conflicto grave aquí, pero la intención no es la de explotar el trabajo voluntarioso de los investigadores, que podrían sentir que no tienen más remedio que participar. Soy consciente de que este es un fenómeno muy importante en la economía del siglo XXI y no me gustaría verlo extrapolado al trabajo académico.
Planes futuros
Al tiempo que alcanzamos el ecuador de Transcribeestoria 1.0, nuestros pensamientos se agolpan inevitablemente hacia lo que podremos hacer a partir de aquí con las herramientas que hemos desarrollado. Podría ser que un trabajo colaborativo o cooperativo como este tuviese una vida corta, sobre todo al comprobar el rápido desarrollo del software de reconocimiento óptico de caracteres con el que se pretende automatizar informáticamente la transcripción del texto de un manuscrito (véase, por ejemplo, transkribus.eu). Ahora bien, la incidencia humana en un proyecto como el nuestro, acercándonos de alguna manera a las huellas de nuestro pasado y ayudándonos entre todos a desentrañarlas, siempre permanecerá. Con este objetivo en el horizonte, nos estamos organizando para colaborar en un futuro con aquellas bibliotecas que contengan más testimonios de la Estoria, a través de un proyecto cooperativo mucho más amplio. Haznos saber si te interesaría participar en él o difundir este tipo de iniciativas.
¡Y mucho ánimo con la transcripción que tienes marcha! El próximo texto, que se publicará el 13 de noviembre, abordará los orígenes del Islam tal como se relata en la Estoria. Será entonces cuando abramos el acceso al manuscrito para cualquier persona interesada en continuar con la transcripción por su cuenta.
Aengus Ward
1 thought on “Transcribeestoria: lecciones aprendidas a medio camino”
Comments are closed.