In this case study we hear from PhD student Elijah Uche, from Electrical Engineering, who has been making use of BlueBEAR to enable his research into remote monitoring of pipeline infrastructure using RADAR sensors for the detection of oil leaks.

The project I am currently working on is the remote monitoring of pipeline infrastructure using RADAR sensors for the detection of oil leaks. As an overview, I create rough surface models in CST with various rms heights and statistics. When these rough surface models are created in CST, I assign a particular dielectric parameter to it, for example, sandy soil which could be wet or dry or even a dry sandy soil that has been soaked with oil. Now after this has been done, from that initial rough surface model with a defined rms height, I try and fill up the rough surface models with water or oil, until it becomes or appears to become a smooth surface.
Now at each level of filling up the holes or cracks which make up the rough surface, I upload the model to BlueBEAR and calculate the reflectivity from each instance. This takes quite a while to calculate just for a model depending on the number of meshes in the rough surface model. Sometimes, the simulation takes at least ten days or even two weeks per model depending on the rms heights as well as other parameters. And mind you, I have over 200 of these models to run for a single simulation parameter.
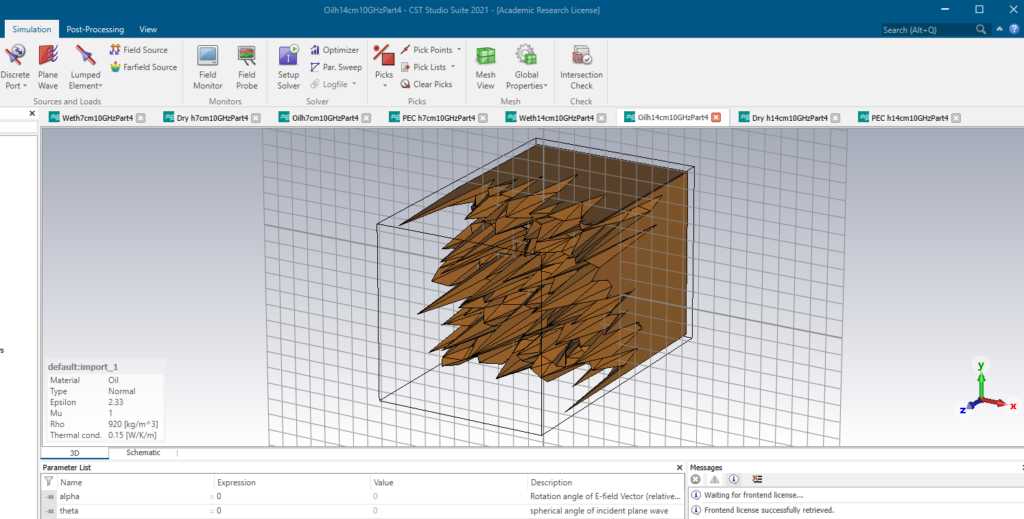
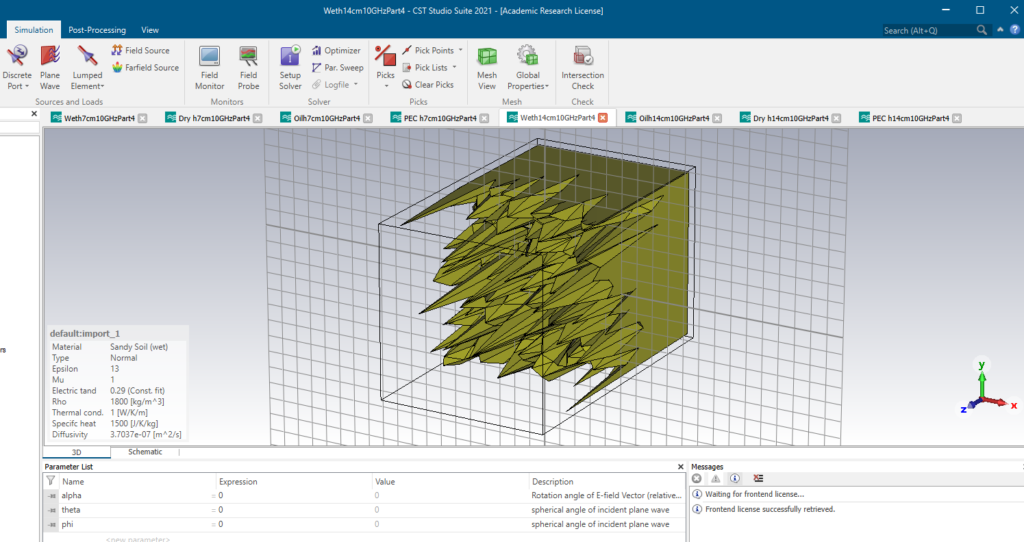
I have tried these a couple of times on my normal University Desktop/PC and every time I run the model, it crashed, the system hangs and I end up forcing the reboot of my PC to no avail. The scale of the data we are working on obviously means that any kind of consumer compute is out of the question.
Our entire dataset can be processed in approximately one week
The University’s supercomputer BlueBEAR was chosen because of the varied requirements that our system demands. We need a scalable CPU compute solution that allows us to perform computations in a massively parallel way, and can run the analyses of our models in a reasonable amount of time. Cloud compute resources of similar quality would be far too expensive for the project and having an all-in-one solution that can easily do these intensive tasks of several CPUs is really useful.
BlueBEAR has solved our problems by giving us access to a flexible system that has both powerful CPU and RDS capabilities. Due to the large amount of intense pre-processing we have to do of our data, the ability to parallelise across many nodes is incredibly useful and has saved us a lot of time!
without parallelisation (which would likely be the case on a standard computer) this would take nearly one month!
The service has essentially made our project feasible by cutting down the time it takes to perform complex simulations. BlueBEAR allows us to run 6 concurrent jobs and this is something we take advantage of. By leveraging all of the compute nodes available to us we can pre-process several apps at once and immediately start the next batch once they are complete. Our entire dataset can be processed in approximately one week. As a back of the envelope calculation, without parallelisation (which would likely be the case on a standard computer) this would take nearly one month!
We were so pleased to hear of how Elijah was able to make use of what is on offer from Advanced Research Computing, particularly to hear of how he has made use of BlueBEAR HPC and its many cores – if you have any examples of how it has helped your research then do get in contact with us at bearinfo@contacts.bham.ac.uk. We are always looking for good examples of use of High Performance Computing to nominate for HPC Wire Awards – see our recent winners for more details.