In the second case study for September, we hear from one of our BEAR Champions, Nezha Acil, about how she has made use of BEAR storage, data processing and our training throughout her PhD, based on studying global forest disturbance data…

My name is Nezha Acil and I am part of Thomas Pugh’s TreeMort team at the School of Geography, Earth and Environmental Sciences, University of Birmingham. I started my PhD in 2018 and will finish my thesis writing by the end of September 2022. The aim of my project is to characterise the patterns of forest disturbances at the global scale and identify storm-related damages based on remote sensing data. This work is funded by the European Commission and is being conducted under the supervision of Thomas Pugh, Jon Sadler and Susanne Suvanto and in collaboration with Cornelius Senf (Technical University of Munich) and Joe Wayman (University of Birmingham). Considering the sheer amount of data needed to describe the structure, context and properties of forest disturbances at a fine spatial resolution, we had to address a number of technical challenges relating to data storage and processing scalability to the global level.
Data Storage
BEAR’s Research Data Store (RDS) offered the best solution for the project’s needs. 3 RDS projects were allocated to my research for a total of 8 TB. This was in addition to two partitions, 2 TB each, on my desktop computer for local data processing. I regularly copy some of the key / finished files to my team’s RDS, where we can share data and co-work. The RDS is automatically and regularly backed up, so any file version deleted or changed accidentally can be retrieved, as long as it existed in previous weeks.
Data Processing
The project required the use of multiple data hosted online on different repositories. I first used Google Earth Engine (GEE) as a single place to access archives and apply routine preprocessing on the cloud. As I needed more flexibility for customizing algorithms, I transferred GEE outputs to the RDS, so I could use the university’s High Performance Computing System BlueBEAR. This gave me the possibility to use tools from ArcGIS’s, Python’s and R’s libraries, process data with up to 500 GB of RAM and massively parallelise job tasks on clusters.
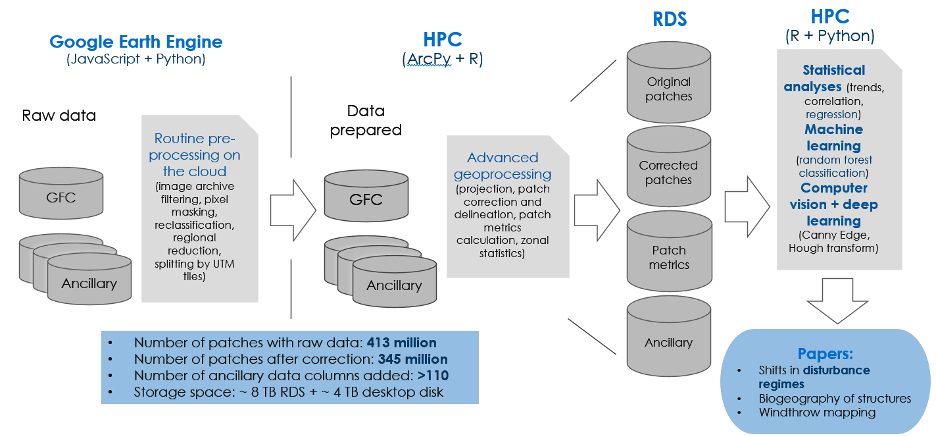
The database produced consists of 345 million individual forest disturbance patches, with corrected geometries, associated with multiple ancillary information in both image and tabular formats. These data are now being used for classifying wind-related damages on forests and will be applied for further modelling purposes.
BEAR Training
Throughout my PhD, I benefitted a lot from the training courses provided by BEAR services. First, the Introduction to Linux and Introduction to BlueBEAR were a catalyst to grasp how to use Linux in supercomputers. I consolidated my background in R and Python, two programming languages that I frequently use since my MScs, with the Software Carpentries workshops. The session on Git was very useful and I still come back to it to remind myself how to sync R Studio projects to GitHub. The 2019 edition of NVIDIA Deep Learning clarified a direction I am envisaging for my research on the use of artificial intelligence for forest disturbance agent recognition. More recently, I completed the NVIDIA Accelerating Data Engineering Pipelines course, which helped me explore ways to optimize my data processing workflow. Finally, BEAR covered my certification as a Carpentries Instructor. The training I received showed me how to efficiently teach programming languages, do live coding and gave me the opportunity to lead a training workshop for an audience of researchers.
It is great to hear of how Nezha has made such good use of various BEAR services on offer, we really value her contribution as both a BEAR Champion, where she has spread the word about BEAR in her area, and as a Carpentries Instructor, where she has helped other researchers to learn how to program. If you’re interested in becoming a BEAR Champion see our post on how to join here. If you have any examples of how BlueBEAR has helped your research then do get in contact with us at bearinfo@contacts.bham.ac.uk, we are always looking for good examples of use of High Performance Computing to nominate for HPC Wire Awards – see our recent winners for more details.