 This post reflects on the Digital Humanities Masterclass 2018 (#DHMasterclass) in which I participated at the German Historical Institute in Paris. [There’s an institute like this in London as well, by the way!]
This post reflects on the Digital Humanities Masterclass 2018 (#DHMasterclass) in which I participated at the German Historical Institute in Paris. [There’s an institute like this in London as well, by the way!]
The masterclass was meant to bring together researchers working with digital tools and historical materials (particularly with autobiographical sources) from France and Germany (and beyond). My main interest in this event was to learn more about the developments of the digital humanities in continental Europe and to meet practitioners working with historical texts. Here I would like to reflect on some of the topics that I particularly enjoyed learning about: the collaborative concept of the event as well as methodological ideas that are useful for my corpus linguistic research, as in the CLiC project, and, finally inspiration for sharing research findings with the public.
Interdisciplinary and international dialogue
 The masterclass was organised with a concept similar to the THATcamp format: the sessions focused on team work and spontaneous hands-on testing of methods on the historical source texts brought along by participants. All along, the programme encouraged dialogue across disciplines and nations: the group included participants with backgrounds in history, German studies, English studies, poetry, corpus linguistics, but also from heritage institutions and archives.
The masterclass was organised with a concept similar to the THATcamp format: the sessions focused on team work and spontaneous hands-on testing of methods on the historical source texts brought along by participants. All along, the programme encouraged dialogue across disciplines and nations: the group included participants with backgrounds in history, German studies, English studies, poetry, corpus linguistics, but also from heritage institutions and archives.
It was especially interesting for me to gain an insight into a diverse range of research projects, their research questions, data sources and methods. In my own experience with corpus linguistic methods, the initial challenge is to identify a suitable corpus or, if such a source doesn’t exist yet, to compile a corpus from relevant electronic texts. However, many of the masterclass participants had access to historical primary sources which had yet to be digitised. Accordingly, digitising the documents can take centre stage in such a project.
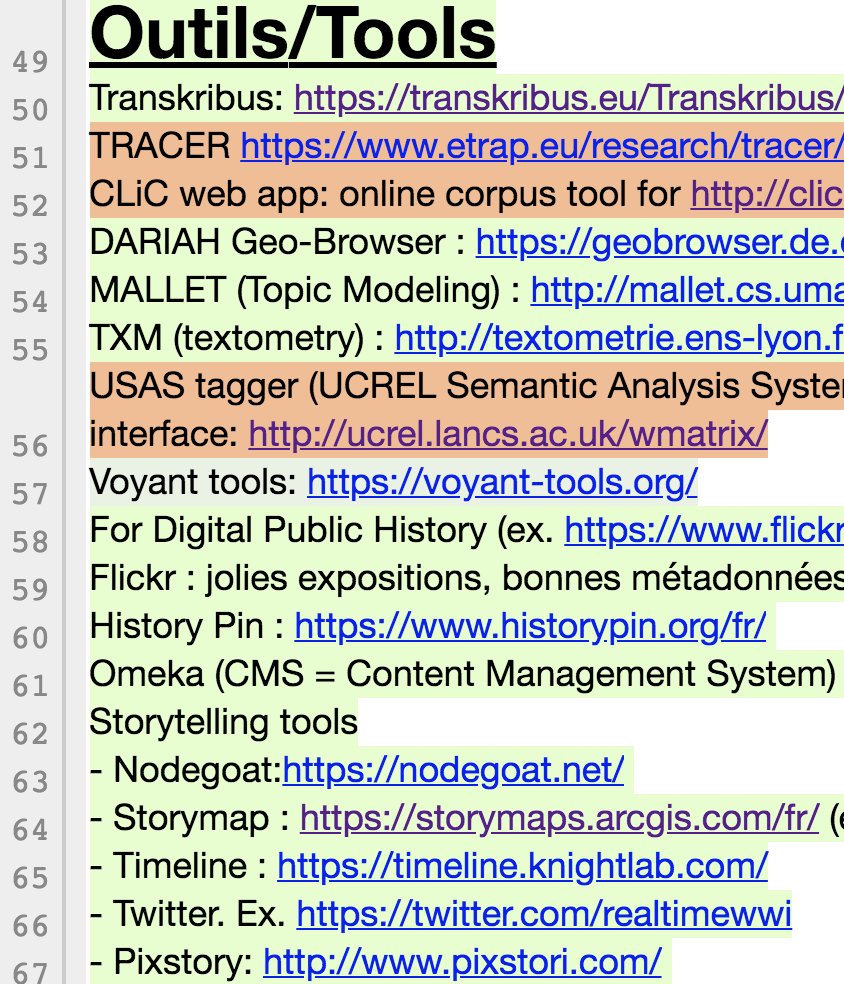
We recorded the insights from presentations and discussions during the masterclass on a “pad” created for the event. In this case we used the French interface Framapad, but there are multiple providers for this type of tool, for example Etherpad. Tools like Google Documents can also be used, although the pad displays more easily who has written which section with the help of different colours (as partly visible in the screenshot). The collaborative writing of notes, comments and links for further reading creates a platform for exchanging ideas during the event. At the same time, the pad turns into a valuable document: although the pad is automatically deleted after several months, it can be exported. In this sense, the pad functions as a joint, dynamic handout – I plan to use it in my own teaching for this purpose. If any of you have used this type of tool in your teaching (or as a student!) before, I’d love to hear your thoughts!
Methodological inspiration
During the masterclass we tried out the Transkribus Tool to automatically transcribe handwritten text. This tool contains a number of preloaded models; if the handwriting does not match any of them, it will have to be trained for the given material. My quick and dirty attempt to transcribe a handwritten ticket by Charles Dickens from a guest post on this blog illustrated exactly what the transcription looks like when the tool does not recognise the handwriting.
Provided that the tool has been correctly trained, the successfully transcribed text can be exported so that the researcher can annotate the electronic text with XML markup for special characteristics of the original document (using an XML editor like Oxygen). Such features might include headings, columns, marginalia, deletions and illustrations.
The annotation enables analyses that aren’t possible with plain text versions of the data, because it makes the material searchable for all annotated elements. Of course, this type of annotation is not only used for digitised versions of handwritten material. The slide in the tweet shows how illustrations can be “encoded” in digital editions of printed books. Obviously, this would be particularly interesting for a 19th century fiction corpus (note the Cruikshank example!). For the annotated texts to be “interoperable” so that the work can be shared across projects, the digital humanities have developed a standard called the Text Encoding Initiative that hosts the full guidelines of the standard as well as advice for learning the TEI.
And there’s even a Dickensian example! #dhmasterclass #CharlesDickens pic.twitter.com/8Hpl706rvJ
— Viola Wiegand (@violawiegand) October 3, 2018
Apart from annotating and encoding, the masterclass touched upon other important concerns for compiling corpora, including legal barriers related to copyright. Andreas Witt emphasised during his session that it is crucial to consider such issues in the early stages of a research project. His talk showed the wide range of applications of corpus linguistic methods for micro- and macro-analysis. For example, on the micro level, the researcher can analyse the use of a particular word (as can be done with our CLiC web app) or by searching the corpus with regular expressions. On the other hand, the analysis may be located on the macro level, as done for research in the tradition of “distant reading“.
Many of the participants were particularly interested in the topic of “named entity recognition”, mentioned by Ioana Galleron. She demonstrated the method with the SEM Tool. In principle, this tool identifies named entities from the categories of “person”, “literary character”, “place”, “organisation”, “company” and “product”. The automatic identification is not perfect, but provides a starting point for the analyst who can then go through the annotated text and correct the named entities manually. Galleron and her colleagues have started a project to identify literary characters (for the initial introduction to the project, see Galleron 2017), which they then annotate in XML/TEI versions of the corpus.
Documenting & sharing
Towards the end of the week the programme focused on the question how to disseminate and record research findings and procedures. This is especially important as the aim of (digital humanities) research is often not only to reach other humanities researchers, but also to raise interest among and integrate the public. To this end, Anita Lucchesi introduced us to the concept of (digital) public history and gave us the chance to start our own small project on the spot. It was fascinating to see how quickly our three groups managed to create interactive online platforms with the tools StoryMap, Timeline und historypin.
Group work for creating a digital public history publication #dhmasterclass 45 min to go. ?⏱ pic.twitter.com/VhSizxK64Q
— Anita Lucchesi (@alucchesi) October 4, 2018
At the same time it is important that real world interactive projects are designed sustainably so that their platforms do not stagnate or the technology stops working. That is why Charles Riondet, Dorian Sellier and Marie Puren from the EU-funded PARTHENOS Projekt showed us how a workflow for such a project can be systematically put in place. Ideally, existing standards should be followed as far as possible in all aspects – not only for tools and file formats, but also for the wording of the documentation. Helpful guidance in this regard is provided in the “FAIR Principles” and the PARTHENOS “Standardization Survival Kit”.
All in all, I thoroughly enjoyed the DHMasterclass week at the German Historical Institute Paris and can only recommend you to participate in events outside your own immediate academic discipline and/or geographic area once in a while. I thank the organisers as well as the Deutsch-Französische Hochschule for the travel grant that allowed me to participate in the masterclass.
What’s next?
The concepts of characterisation and mind modelling in fictional text is very important in corpus stylistics in general – and one of the central focus areas of our CLiC project. [For an introduction to the CLiC approach see for example Stockwell & Mahlberg 2015]. I was therefore delighted to find Galleron’s talk on literary characters on the masterclass programme.
There appear to be many parallels between the digital humanities approach to annotating fictional texts for literary characters and the corpus stylistic approaches to analysing textual patterns relevant to characterisation. The Framapad and my personal notes are full of methods and concepts for which I plan to check further reading and deepen my understanding. But most importantly, I am very glad to have met colleagues from so many different backgrounds at the masterclass, because dialogue across disciplinary and national boundaries is crucial for researchers.
If you would like to learn more about the developments of the European digital humanities and specifically what’s being done with literary texts, check out the Digital Literary Stylistics special interest group (SIG-DLS) (you will also find an introduction to CLiC on their blog!). In the meantime, I’d love to hear your thoughts on anything I’ve touched upon. Have you used any of the tools or methods described here? Have you attended a similar event? What impact has the experience had on your work? Feel free to leave a comment below 🙂
Bibliography
- Galleron, I. (2017). Conceptualisation of Theatrical Characters in the Digital Paradigm: Needs, Problems and Foreseen Solutions. Human and Social Studies, 6(1), 88–108. https://doi.org/10.1515/hssr-2017-0007
-
Stockwell, P., & Mahlberg, M. (2015). Mind-modelling with corpus stylistics in David Copperfield. Language and Literature, 24(2), 129–147. https://doi.org/10.1177/0963947015576168
Please cite this post as follows: Wiegand, V. (2018, November 9). Inspiration for corpus linguistics and stylistics: #dhmasterclass [Blog post]. Retrieved from https://blog.bham.ac.uk/clic-dickens/2018/11/09/inspiration-for-corpus-linguistics-and-stylistics-dhmasterclass
This blog post was adapted from its original German version, published on the Blog of the German Historical Institute Paris.
Join the discussion
0 people are already talking about this, why not let us know what you think?